
Making Arguments with Data
Resisting Appropriation and Assumption of Access/Reason in Machine Learning Training Processes
1 Introduction
The outputs of machine learning (ML) algorithms play an increasingly important role in decisions that concern both personal and global socio-political and economic choices. Patterns and trends identified by ML models in large datasets, or ‘Big Data,’ are considered sources of truth and reason in various areas such as recruitment and admission processes, pandemic management measures and individual purchase decisions. However, there is limited access to examine the processes and sources that inform these decisions. Tools and frameworks such as Google’s Colab,1 OpenAI’s GPT3,2 or design-specialized tools like CLO 3 or RunwayML 4 come with pre-trained models, accessible to anyone with a computer and internet. These models are already influenced by inherent assumptions and biases that stem from data collection, organization and storage methods. Furthermore, the algorithmic predictions might already be influenced by pre-established correlations between real-life processes and ways these can be effectively datafied.
Datasets and digital archives offer comprehensive lists and systematizations of details documenting diverse natural and social phenomena, such as European animal datasets, world temperature and precipitation measurements, or web images. Scholars in digital humanities, like Miriam Posner and Lauren F. Klein (2017), have highlighted that data is always pre-categorized in some manner, leading to the presumption that these categories are inherently meaningful. Tahani Nadim, a cultural anthropologist, has critically discussed the impact of such categorizations on the understanding of nature. For instance, the taxonomic categorization of a European animal dataset tends to reflect the taxonomic gaze of European 19th-century natural history collections, with their colonial blind spots, resulting in a systematization that renders entries manageable and computable (Nadim, 2021). Databases are not passive containers of data; they facilitate certain rationalizations while hindering others, and their historical context and practical differences are crucial factors to consider.
Machine learning models are inseparable from the datasets that these statistical algorithms use to analyze data. Therefore, critical data studies emphasize the ways in which datafication, as introduced by Mayer-Schönberger and Cukier (2014), has benefited governments and corporations at the expense of people’s liberty and privacy. In her work on race and technology, sociologist Ruha Benjamin (2019) identified this as engineered inequity and default discrimination. Furthermore, computer scientist Cathy O’Neil (2016) observed that taking correlations between data, such as employment history and address, at face value is at the root of discriminative operations of algorithms . Recent research has proposed some technical solutions to address this issue. For example, frameworks for dataset development transparency have been offered to support decision-making and accountability (Hutchinson et al., 2021). To change this, the argument presented in this paper suggests that we must start from the dataset and reimagine the expectations we set for training processes and trained models.
Artistic practice demonstrates how to constructively counter the assumptions and biases that permeate automated processes of training on datasets. For example, in a recent experimental theatre piece by the artist Simon Senn and developer Tammara Leites titled dSimon,5 an artificial personality was performed as a conversant, artistic advisor and a stand-in for Elon Musk and Simon Senn himself. The dramatic unfolding of the incurably inappropriate behavior of the dSimon conversation agent, trained on Simon Senn’s personal data using OpenAI’s GPT-3 deep learning language model, engaged the audience as witnesses to bizarre and unsettling propositions. The illusion of neutrality in vast collections of internet-based text quickly dissipated, revealing the inherent sociality of anyone’s or anything’s ability to understand and compose language. Other relevant examples of artists working with datasets include Anna Ridler’s laborious hand-labeling of tulip photographs to construct the dataset for her Mosaic Virus,6 from which a generative adversarial network (GAN) algorithm constructs images of possible tulips. The spectator of the moving image can observe the formation of a concept of a flower in the visual performance of the algorithm. Artist Mimi Ọnụọha proposed a speculative intervention into archival media in the form of naming and documenting Missing Datasets.7 Ọnụọha carefully identifies blank spots in spaces that are otherwise data-saturated, such as officer brutality in policing data. The artistic projects discussed above productively address bias and latent uncertainties in datasets by demonstrating and dramatizing the processes by which data collection and ML potentially inflict violence or injustice. They bring attention to the ambiguity of outcomes in the collection and processing of data and propose a myriad of alternative, non-instrumental ways to work with datasets.
This article combines the technical and artistic perspectives on bias, assumptions of access and other forms of structural violence in the applications of ML models. It is informed by critical data studies and critique of contemporary aspirations for objectivity in ML applications. The central argument engages with the critique of scientific aspiration to universal objectivity, as addressed by Donna Haraway (1988, 2016), Sandra Harding (1986), Jane Duran (1991), Linda Alcoff and Elizabeth Potter (1993), as well as the extensive debate on objectivity in science, as Lorraine Daston and Peter Galison (2007) recounted. This critique is extended to the insufficiency of openness, Christina Dunbar-Hester poignantly showed (2020) through her ethnographic study of the voluntaristic address of social inequality in open-technology communities. While open software and open hardware have established themselves as a countermovement to the restrictions imposed by proprietary developments in the industry (Newman et al., 2016), technologically-driven openness overlooks the political question of social inclusion and equity. Therefore, the article addresses questions related to openness and democratization in the context of concerns for bias and injustice propagated by ML and artificial intelligence (AI). The article also includes a critical reflection on access beyond openness, drawing on anti-colonial scholarship that demonstrates the close entanglement between assumptions of access and colonial relations. The work of pollution scholar Max Liboiron at CLEAR lab in St. John’s, Newfoundland and Labrador, Canada, is specifically discussed as an example. Assumptions of access can enable seemingly unproblematic pollution of the environment up to a specific ‘assimilative capacity’ (Liboiron, 2021). This concept is extended to the domain of ML, where there is a presumption of unproblematic access to extensive datasets for training the models. The article further discusses the need to envision different ways of working with datasets and ML models, enabling people to formulate situated arguments based on the relations they actively discover in the data and trained models.
Reflections presented here serve as an introduction to the issue of access to and readability of ML algorithms and training datasets, with a specific focus on data collection processes. The authors present two practical examples that demonstrate unconventional and non-instrumental ways of working with large datasets. These examples draw from the authors’ research and teaching practice, exploring modes of interaction with ML systems. In the first example, the paper explores how ML models can be navigated in a multi-narrative manner. The authors programmed and utilized web-based interfaces to sort, organize and explore a community-ran digital archive of radio signals called SIGID wiki.8 The second example addresses the use of a specific dataset, the LAION-5B,9 to train a state-of-the-art ML image synthesizer known as Stable Diffusion. The discussion centers on how the pre-trained ML model can only reproduce images available within the dataset, thus reinforcing the worldview of the dataset itself and excluding other perspectives. Both examples extend concerns for bias, openness and access to datasets and ML models into the realm of interactions. They present exploratory approaches to ML models and offer a multitude of coexisting possibilities. Such interactions with computational logic complicate the aspirations of universal objectivity commonly associated with ML systems’ pursuit of sufficiently probable predictions or meaningful correlation (Joque, 2022). The aim of our work is not to challenge the possibility of science or scientific objectivity. Instead, we seek to challenge the universality of predictive and decision-oriented approaches in ML, which often conflate “guess[ing] the correct outcome with a high enough probability” (Joque, 2022 loc. 702) with an objective accurate assessment of possibility or risk.
2 Resisting Appropriation and Assumption in Machine Learning Processes
According to anti-colonial pollution scholar Max Liboiron (2021), appropriation and assumption of access are fundamental mechanisms of colonialism, through which Land and relations are subsumed for profit-making purposes. In classical pollution science, the assumption of access is manifested in the concept of environmental capacity, which considers the environment as a sink capable of assimilating specific levels of pollution, thereby maintaining the existing status quo. Coincidentally, contemporary relations with ML technologies also exhibit appropriation of data relations and presumption of access. These assumptions are reflected in the way data is fed into ML models, the presumption of access to the content people upload on social networks, and the extrapolation of assumptions about the future derived from ML models. The current landscape of ML includes many user-friendly tools that are accessible to people without a computer science background or coding skills through cloud-based frameworks. These tools run on remote servers with substantial computing power, which cannot be achieved with regular laptops or PCs. While the accessibility of these tools may seem uncomplicated, it relies on a well-oiled backbone infrastructure built on machines that generate heat, noise and consume significant energy and material in their components. When presented in an easily accessible form, such as a website prompt, these ML tools operate with a limited set of options already predetermined by the dataset and the connections established by the ML model. Many potential outcomes are filtered out, leaving only a restricted range of possibilities.
In the book Hacking Diversity, Christina Dunbar-Hester (2020) works to evaluate the political potentials and limitations of voluntaristic interventions into diversity questions. Open-source and open-technology communities constitute a laboratory for the voluntaristic address of social inequality, with a strong commitment to self-governance and autonomy. While sympathetic to the communities studied in this research, the book shows that interventions driven by the motivation of access to technology are insufficient to tackle structural social problems. On the one hand, a robust appraisal of power and technology’s role in reproducing social orders is needed. On the other hand, emancipatory politics needs to be carefully disentangled from technical engagement, paying attention to the slippage between diversity in technical participation and calls for social justice. Dunbar-Hester (2020) writes “Access and emancipation are politically charged ideas: they offer liberal subjects inviting opportunities for self-determination as individuals and as collectives” (Dunbar-Hester, 2020, p. 10). The communal and shared actions that characterize hacking and Free-Libre-Open-Source Software (FLOSS) communities are agnostic and denying of formal politics, making them unlikely and difficult sites for gender and diversity activism.
Working with data entails taking a position and formulating a clear goal. Even if the term ‘data’ is correctly translated from the original Latin term as ‘given,’ it is not simply given and is always collected with certain logics of measurement and observation. In our work on the ‘critique from within,’ we acknowledge that data and analysis never speak for themselves, as anti-colonial pollution scholar Max Liboiron (2021) illustrated. The presumption of unproblematic and unaccountable (often referred to as objective) data collection reproduces colonial relations to resources and reality. Liboiron also emphasizes the importance of caring for the subject of critique.
Scholars in the social studies of science and technology have addressed the problems that arise with the use of pre-trained ML algorithms as decision-making and forecast tools (Benjamin, 2019; Graham et al., 2019; Halpern & Mitchell, 2022). These models often replicate biases encoded in the data they are trained on. As a result, the reverberation of such biases has already manifested in automated decision-making processes, leading to racial and gender preferences in the selection of job candidates, admissions to studies, decisions on incarceration and parole, or loan approvals.
Similarly, in artistic practice, tools such as Runway ML,10 provide artists and designers with prebuilt ML models and a pay-as-you-go system to deploy heavy computing ML on remote servers. For creative practitioners, the software offers access to several basic ML models, including text generation, image synthesis and object detection. The result displays predictions of their trained algorithms given an input by the user, but without showing the data or the process of the prediction. This approach could be described as ‘arboreal’ in terms of Deleuze and Guattari’s rhizomatic theory (Deleuze & Guattari, 1976), as it preserves a tree-like hierarchical conception of knowledge and information with discrete categorization. This confronts the user with a tool that does not grant access to understanding the underlying technology of ML, such as statistical analysis, data clustering and prediction. By denying access, such tools reproduce a colonial-like relationship of entitlement, where resources such as computational power and algorithms are claimed by those who operate them in their best self-interest. This simultaneously organizes and extracts the work of their nomadic11 users.
To address such biases, US-based artist and researcher Caroline Sinders led practical workshops to create feminist datasets.12 Data collection informed by intersectional feminist practices aims to mitigate the effect of biases in ML algorithms by critically engaging in the data collection process (Sinders, 2020). Sinders’ workshops invited the public to explore the meaning of data and its use for protest and social justice. In a related effort, Crag Dalton and Jim Thatcher (2014) called for counter-data actions. Dalton and Thatcher offered provocations that recognized the situatedness of the regime of ‘big’ data, the risks of technological determinism and challenged the notion of data being ‘raw.’ While current software for ML algorithms often lacks access to the data they are built upon, critical approaches to data collection in academic settings, or workshops within festivals and seminars, promote a discursive approach to the topic but may lack a more technical approach.
Radio transmissions, as discussed later in this text, belong to the infrastructural engineering domain, which is not readily accessible to radio amateurs. In this context, we approach the scattered documentation about the use of electromagnetic energy for telecommunications as an opaque and unreadable yet highly informational dataset. Our aim is to establish relations between data points that are not motivated by an instrumental lens, or indeed, hard to make sense of. Similarly, when working with ML-powered image synthesis, we will demonstrate the potentials and limitations of image (re)production using a pre-trained ML model. Through this process, we will disclose the worldviews that inform the data collection, which can be inferred from the results.
The paper documents the search for ways to develop and work with digital tools that encourage critical engagement with data. It involves formulating questions one wants answered by information before observing patterns in the data and clearly expressing one’s position regarding the question. The paper highlights a gap between theoretical approaches to data science critique and critical data studies (Benjamin, 2019; D’Ignazio & Klein, 2020; Nadim, 2021; Posner & Klein, 2017) and more practical approaches that make use of computation to create datasets (Sinders, 2020) and model relationships in data. We have developed practical approaches to dataset creation and interpretations of ML models. While they work with data that is collected and made available to facilitate identification, such as correctly identifying radio signals in the wild (SIGID wiki) or visual concepts in images (LAION-5), we do not aspire to contribute to the project of identification and want to distance from any such a priori instrumental classification of data. We insist on multiple readings and aspire to extend theoretical considerations for bias, access and openness into the domain of practical engagement with datasets and ML models. Through our work, we hope to contribute a clear example of how to work with large datasets and ML technologies in an informed way that promotes participation and intentionality.
3 Image Explorations: Training, Selecting, Synthesizing
In this section, we will take a detailed look at how an implementation of a ML framework, namely the LAION-5B dataset-based Stable Diffusion algorithm by Stability AI, simultaneously propagates and dispels the myth of open and democratizing technology. We will describe the process of synthesizing images using the opaque yet accessible tool and platform. The choice of the ML system is not arbitrary. Unlike OpenAI Dall-e and Midjourney, Stability AI’s image synthesizer model is fully open source. This is significant as the ML model provides access to the dataset it is currently trained on. Despite the political choice of offering the source code and dataset openly, the Stable AI is currently a viable alternative to image synthesis models available behind a paywall. The first step is to create a couple of accounts: Google Colab and Hugging Face; the latter is a repository for ML systems that can be installed directly on a private computer. The steps needed to have the Stable diffusion ML model working include creating a new Notebook on Google Colab and pasting the code given in the Hugging Face repository. Subsequently, to access the necessary GPU computing, a $9.55 fee needs to be paid to Google. Once that transaction is completed, it is possible to run the Stable diffusion AI on remote but privately owned processors (GPUs). Therefore, with less than $10, it is possible for almost anyone with an internet connection and a personal computer to run a complex ML algorithm for image synthesis.
Such operations carried out by big tech companies are frequently portrayed in popular culture and policy as democratizing a specific technology, in this case, AI. However, the issue concerning the democratization of AI is one of semantics. The narrative of democratization often suggests a benevolent act of care aimed at enhancing the social condition of humanity. Unfortunately, this gesture often replicates what Max Liboiron described as (colonial) paternalism and annihilation, similar to the imposition of Christian and settler state logics of care through Canadian residential schools (Liboiron, 2021, p. 115).
Loading a ML model on Google Colab can be likened to using face filters on Instagram – a convincing and contextual image modification tool, yet offering only a limited set of options. While a Google Colab model can be extended to combine other ML models, it does not provide the possibility to build a new ML model. This limitation arises because ML models are socio-technical constructs comprising data, statistical analysis algorithms, parallel processing hardware like GPUs, labor and capital. When these five elements are combined, ML models are generated in both the academic and private sectors. This process can be described as a nexus between power and knowledge, borrowing the words of Foucault (2007), where the politics of the model’s owner and the labor force involved in its creation are infused into the model, reproducing a specific worldview. This is the gesture that reproduces forms of colonial paternalism and annihilation. The ML model is there to be openly and widely used but by using it, a specific worldview is reproduced, constructing new normality to the annihilation of anything that lies outside of such worldview. An example of such is the whiteness of results when prompting ‘person doing gardening’: all images include a white person doing gardening. This highlights the semantic problem discussed earlier: democratization only applies to access to specific prebuilt ML algorithms, and it does not democratize the predictive technology underlying Stable Diffusion algorithms.
These claims are substantiated by the experiences of a class taught by one of the authors in collaboration with Paulina Zybinska at the Zurich University of the Arts, ZHDK. During the interdisciplinary class “Synthetic Normal,” students were tasked with exploring the tension between the inherent biases of ML algorithms and the optimism for more equitable and inclusive datasets. The class was introduced to various ML algorithms, and among them, Stable Diffusion proved to be the most popular due to its image synthesis capabilities. For their first assignment, students were required to create a Twitter bot that automatically posted images on a topic of their choice. They were also asked to reflect on how the ML model depicted synthesized normality. The primary aim of the assignment was to provide students with an opportunity to critically reflect on how such a system reproduces and generates pre-configured worldviews. The BA students from interaction and game design backgrounds were already well aware of the issues surrounding ML systems. They quickly recognized the problems with the images they generated, going beyond the problem of representation in the dataset. For instance, one student used Stable Diffusion to represent dogs engaging in normal human activities. Interestingly, the algorithm consistently returned images of a very specific breed of dogs: golden retrievers, even when the prompt contained only the word “dog.” While this outcome may not be directly comparable to the racial stereotypes found in the training sets and outputs of algorithms, it is nevertheless indicative of the representation of dog breeds within the dataset used to train Stable Diffusion.
We would like to suggest that the problem with the golden retriever goes beyond the limitations of representation in the dataset. The process of openness and democratization of such ML algorithms is not only a matter of giving access to its operation, but it is also an effort of global-scale adoption of a specific image synthesis algorithm. As the companies providing these tools are inherently profit-driven, the question of diversity and inclusion is similarly approached from an economic perspective. The cost of training a dataset to be more inclusive is significant, making the re-training of a complex generative model expensive. Therefore, training it for inclusion comes with a hefty price tag.13 The transfusion of economy and politics into technical artifacts, commonly known as bias, is also publicly disclosed by the architects of such ML models. For instance, the Hugging Face repository explicitly states the limitations and biases of their own model, providing potential users with a transparent and candid warning about the Western worldview their model may exhibit. This is because it was trained on the LAION-2B-en dataset, a subset of the LAION-5B dataset containing over 2 billion images labeled in the English language. The dataset itself was constructed and is maintained by a non-profit organization funded by donations and public research grants.14 On the other hand, the Stability AI team, which developed the Stable Diffusion model, is a privately owned company. The development of the model has been carried out by a larger team than an average layperson using their model could ever afford to have.
The process of developing AI is far from democratic because it is still very complex and expensive, relying on the funding and expertise of a small number of actors, mainly in the industry. Moreover, creating a dataset large and “reliable” enough to retrain such a large model is a complex and costly endeavor. This dataset creation process reproduces a power/knowledge nexus where the politics of researchers, donors and state funding schemes are entangled to perpetuate their own worldview. For instance, when the artist Anna Ridler photographed and labeled her own dataset of 10,000 tulips during a 3-month residency in the Netherlands, she took upon herself the task and responsibility to produce a coherent and reliable dataset.
4 Radio Explorations: Data Observations, Projections and Comparisons
The Negentropic Explorations of Radio research project,15 which ran from 2020 to 2021, provided us with the space and data to experiment with establishing coherent digital (id)entities using unsupervised ML tools. We based our work on a publicly accessible digital archive of radio signals known as SIGID wiki. Through this project, we designed data observatories as intuitive tools for orienting and navigating within the dataset. Our principal aim was to develop and practice techniques for working with digital data in an ethically sensitive manner that considers biases and universalism while highlighting material and symbolic connections with the world. Capturing radio signals requires dedicated radio equipment, either amateur or professional, and this process closely resembles naturalist observations such as bird watching or identifying plants. Contributors to the SIGID wiki archive capture radio signals ‘in the wild,’ similar to how one would pick alpine flowers or record the call of a bird, and then analyze and compare these captured signals to databases of known species or signals. However, unlike a bird song, the recording of a radio signal is inaccessible to human senses and impossible to make sense of directly. Thus, comparison between individual radio signal recordings is always mediated by computational tools. This unique characteristic makes radio signals an intriguing case for further developing computational comparison techniques. In the Negentropic Explorations of Radio project, we developed and utilized a tool that enabled comparisons between patterns in the radio dataset. This practice fosters a distinctive relationship between the data, the method of comparison and the questions that we bring to the data.
The Signal Identification Guide (SIGID) wiki is a comprehensive collection of information about radio signals maintained by a community of radio amateurs and enthusiasts. It houses data on various signal characteristics, including frequency, bandwidth, modulation type, as well as short descriptions, audio samples and waterfall plots. As implied by its name, the primary objective of the website is to aid in the identification of signals captured by contributors by comparing them to existing entries in the database. The community of people interested in radio signal–based technologies use the website for a variety of purposes. Any radio signal that can be received and recorded has the potential to be included in the database, either as a sample of a previously described radio signal or as an unidentified signal that awaits identification.
The dataset used in this experiment comprises recordings from the digital archive of radio signals, focusing on specific aspects of these situated recordings of radio transmissions. We computed features, such as noisiness or the probability of silence, in samples of radio signals found in the database. By examining radio signals from a particular level of abstraction – the extracted features of the recording – we constructed a shared landscape of properties, organizing the data based on the conditions of the comparison.
We utilized an unsupervised ML algorithm, the self-organizing map (SOM), on this unlabeled dataset. The SOM’s artificial neural network organizes properties of radio signals, including the probability of silence, the level of noise in the audio sample and an audio identification technique called fingerprinting.16 The observatory is visualized as a vector space, with codebook vectors connected in a topological arrangement. Each property of the archive corresponds to a different informational face. Through the SOM training, topological relationships are established, determining how radio signal samples are placed next to each other on the map. Direct similarities between radio signals on the map reflect their likeness in shared aspects, even across seemingly unrelated signal recordings. These comparisons offer new insights into relationships that can be established across datasets and do not necessarily lend themselves to causal interpretations (for example, instrumental causality would match two signals used for similar purposes) and superficial correlations (for example, a formal similarity in rhythm or frequency). While certain signals may be similar due to shared protocols or application domains (for example, military or satellite communication), the approach described here allows us to disregard instrumental qualities of telecommunications and focus on how digital data can be compared on its own terms. This means that digital data on radio signals can be rendered comparable to other types of data, such as music samples or bird song recordings. Moreover, this perspective allows us to identify inherent properties of data that emerge from the comparison process. Instead of understanding radio solely in terms of its capacity to transmit messages, we explore how digital traces of radio signals interact with recording equipment – a perspective we develop in this subchapter.
The visual aspect of comparison and navigation is also crucial in this work. Figure 1 illustrates the organization of the two datasets mentioned earlier, where radio signals are juxtaposed with musical genres. Visual qualities of radio signal spectrograms enable us to step back from an instrumental perspective on radio signals, moving away from their typical categorization based on applications or frequencies. Instead, the signals are represented as abstract visual patterns that retain certain qualities related to these instrumental concerns. Visual interpretation plays a dual role: it aids in comparing signals, allowing us to identify patterns and relationships, and enables us to understand how the tool itself operates.
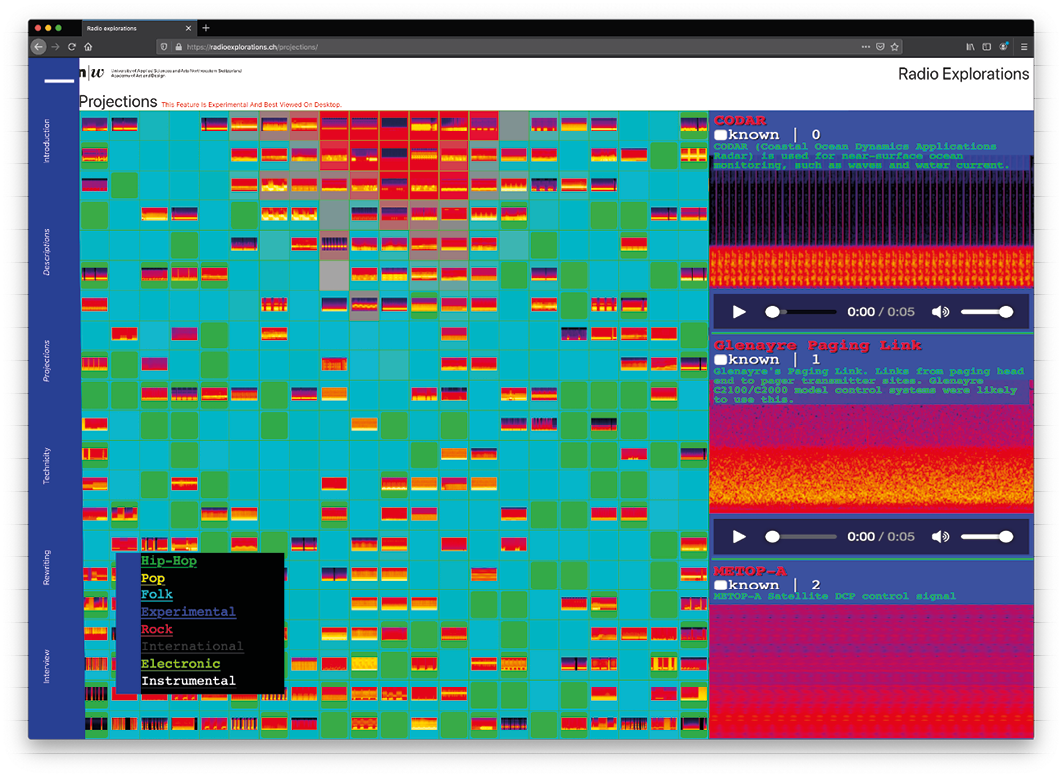
Figure 1. Negentropic Explorations of Radio. Signals are ‘projected’ onto a pre-organized map of musical samples, labeled according to the genre (overlay, bottom left). Each genre ‘highlights’ some cells among which certain radio signals can be found. Highlighted here is the ‘Hip-Hop’ genre.
The interface of the data observatory pictured in Figure 1 provides access to all signals based on their placement in the 2-dimensional grid of the SOM. Multiple signals are grouped together in the same ‘cell,’ and each cell can contain several signals that are computationally similar, based on the extracted feature of their sonic representation. To emphasize their similarity, a ‘projection’ process is used, where each radio signal is individually compared to an already organized SOM of music samples from the FMA dataset.17 This comparison reveals that all signals within a cell are not only similar to each other but also share similarities with the song that characterizes that cell. For instance, the radio signal protocol CODAR,18 used for monitoring ocean waves and water currents, is informationally similar to the mostly obsolete paging link signal, Glenayre19 (as seen on the right side of Figure 1). This similarity is based on their comparison to a dataset of music samples, which includes various music genres, including hip-hop. The informational face of hip-hop in the interface (green highlighted squares) reveals this comparability between the two known signals and extends the comparability to some unknown signals, potentially aiding in their identification. The chosen example illustrates an interesting collocation of otherwise unrelated signals. By exploring this collocation in-depth, researchers can consider specific historical and technical aspects of these radio signals in the context of their apparent similarity. Overall, the data observatory establishes situated relationships between data points of different kinds and origins through computationally quantified comparisons of their informational qualities.
Any dataset can result in a multitude of data observatories, each focused on different aspects or properties of the data that we might want to explore. A data observatory is not limited to just one, and there is no exhaustive number of observatories for any dataset. It encodes the interests or perspectives of the observer, such as comparisons of datasets or similarities between radio signals’ informational content. The informational face or topological arrangement of the observatory emerges from the intersection of an observer’s interests and the specific aspect of the data they are working with.
5 Resisting the Assumption of Access and Reason
Several ideas for novel approaches to making arguments based on relationships in datasets and archives were discussed in this article, drawing from the perspectives of new materialist and science and technology scholars. The authors also conducted specific experiments to explore these ideas further. One of the ideas in circulation is inspired by Tahani Nadim’s short text on the Database, where she proposed finding new ways of mining and undermining the evidence of the archive (Nadim, 2021). Nadim suggested moving away from the impetus of discovery and instead focusing on mobilizing traces through narration and interpretation (Nadim, 2021). Her proposal for data fictions as crucial elements for achieving different kinds of visibilities and transparencies is considered valuable in this context. It is important to recognize that every archive, database and archival practice carries its own set of beliefs and hopes, aiming to advance accuracy and capacity for reasoning with the data it contains.
Intersectional feminism raises significant questions about methods for working with data and classification. Scholars like Miriam Posner and Lauren F. Klein questioned the meaningfulness of categories in archives and drawn connections to feminist theory, particularly the work of Judith Butler, Donna Haraway and Karen Barad, to challenge repressive systems of classification (Posner & Klein, 2017). In Data Feminism, Catherine D’Ignazio and Lauren F. Klein (2020) explore intersectional analysis to understand how systems of datafication and classification perpetuate oppression. They acknowledge an initial impasse: to be utilized, data must be classified in some way. This echoes the work of Bowker and Star (2000), who considered classification as essential for any functioning infrastructure. However, once the system is in place and operational, it becomes ‘naturalized,’ leading to the assumption of rationality or givenness of certain relationships or categories, which are socially constructed and the result of labor. In other words, data is always recorded, collected and classified through the work of someone or something. This aligns with the critique of database ontology in information studies, which implies a hierarchical representation of knowledge based on a singular logic of the world (Juliano & Srinivasan, 2012, p. 619). Within databases, normative categories are constructed. Expanding on this critique, data feminism of D’Ignazio and Klein (2020) examines the uses and limitations of datasets, informed by intersectional feminist thought that pays attention to power and knowledge relationships in the processes that produce or result in data.
As discussed in the introduction, the past five years have witnessed the emergence of tools that grant access to ML algorithms and pre-trained ML models to anyone with a computer and internet connection. Google Colab, for instance, offers access to a wide range of ML algorithms, thanks to its extensive infrastructure of ML-ready computers. Its implementation of the Jupyter notebook and sharing capabilities make it a popular choice for individuals who wish to experiment with AI but lack the budget or technical expertise to set up their own machines capable of running such models. This progress is often celebrated as the democratization of technology, promoting openness and accessibility to AI.
Posing the issue of access solely as a matter of openness in connection to freely available technology like Colab notebooks overlooks the potential to address access in a political context and fails to consider the specific ways in which access is facilitated. Christina Dunbar-Hester’s (2020) ethnographic study of hacker and FLOSS communities illustrates that technology, as a realm of knowledge and action, does not automatically translate into a comprehensive critique of systemic oppressions and exclusions. While openness is valued, it also demands specialized knowledge, time and resources to engage effectively with open and free projects.
In the case of Stability AI and Colab algorithms, the tools depict a specific worldview that is shaped by someone other than the person who wants to synthesize images or generate text, thereby excluding all other perspectives. It is essential to emphasize this exclusion and recognize the significant role that data plays in shaping these biases. Therefore, a truly democratic AI would not only expose biases, as the Stability AI team did, but also provide proper ways to overcome this exclusion, going beyond the current practice of enlarging datasets to make them more diverse. Inclusivity should be measured not only in quantitative terms but also in granting equitable access to dataset production and their training for ML models.
Building upon the theoretical and practical proposals discussed here, such as Caroline Sinders’ feminist datasets or Tahani Nadim’s data fictions, we have developed practices that situate and specify these proposals in concrete datasets, such as radio signals, in concrete ML algorithms, such as the SOM, and in concrete models, such as the Stable Diffusion model. By programmatically exploring the interactions we can envision and develop with these concrete instances of data and algorithms, we extend the reflection and critique of data collection and data representations, making them more vulnerable to scrutiny. Regarding the assumption of access, our work with SIGID wiki radio signals and LAION-5 images dataset aims to bring forth the stories of data collection and the knowledge involved in capturing and structuring those datasets. For example, with the data observatory interface, one can explore the history, technical details and relationships with other signals through their collocation. This intersection of concerns shows that even a technical artifact, such as radio, cannot be fully understood through engineering knowledge alone, nor can it be reduced to a singular perspective. With a nod to Judy Wajcman’s technofeminism (Wajcman, 2004) and the broader STS argument on the co-production of society and technology, we stress the importance of understanding ML technologies as materialized expressions of social relations.
6 Conclusions
The recent rise of data-driven technologies in everyday use, such as classifiers and recommender systems, has brought attention to the problem of biases within data and vocal criticism of automated ML-powered technologies. Nevertheless, such criticism often precludes alternative ways to use such technologies that can be steered towards new modes of expression and argumentation. We started the discussion on alternative ways to work with ML and large datasets with a reflection on artistic projects that question, challenge and repurpose these technologies for different processes and goals. We developed a technical framework that comprises a digital tool for data processing and analysis within the Negentropic Explorations of Radio project and used it to explore multi-threaded narratives of music and telecommunication, power and efficiency, encoded in the datasets we worked with. By combining the concern for the importance and persistence of vision vision (Haraway, 1988) and its access to complex relations in the data through interfaces, with the concern for digital sovereignty expressed as a resistance to colonial relations that haunt digital tools and knowledge of technical artifacts, we suggest paying attention to the processes that establish these relationships and situating any claims that can be made about their relationship within the specific research questions raised.
We are also concerned with the problematic use of words like “openness” and “democratic” in relation to ML systems. As discussed in section 3, the output of a specific ML algorithm is always related to the data it was trained upon, and despite the availability of various open datasets, complex ML systems like image and text synthesis being developed now require highly skilled labor as well as substantial funding. Therefore, it is impossible to separate the algorithms of ML from the datasets they are trained upon, especially considering the intense care and labor required to construct the latter. This demonstrates how questionable it is to fully render such technology truly open and democratic.
With our two examples, on radio and images, as well as the broader discussion on openness and democratization, we show that the main challenge to active participation of citizens in digital transformations comes from lingering forms of colonialism and extractive relationships that easily move in and out of the digital domain. These include limited access to datasets used in popular ML frameworks, and non-permissive costs of developing technologies offered ‘for free’ to the public. These concrete cases articulate exploratory approaches to ML systems, both the readily available models as well as training processes, and extend concerns for bias and access to datasets into the domain of interaction. The projects discussed offer insights into the specificities of data collection of radio signals and image files, which bring along the assumption of access, categorization and interpretation practices of specific communities that create these datasets. With this paper, we want to invite the reader to rethink ways to engage with data together, to take the space and structure of datasets as material to actively work with, question and modify.
References
Alcoff, L., & Potter, E. (Eds.). (1993). Feminist epistemologies. Routledge.
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim code. Polity.
Bowker, G. C., & Star, S. L. (2000). Sorting things out: Classification and its consequences (1st paperback edition). The MIT Press.
Braidotti, R. (2011). Nomadic Subjects: Embodiment and Sexual Difference in Contemporary Feminist Theory. Columbia University Press.
Dalton, C., & Thatcher, J. (2014, May 12). What Does A Critical Data Studies Look Like, And Why Do We Care? Society and Space.
https://www.societyandspace.org/articles/what-does-a-critical-data-studies-look-like-and-why-do-we-care
Daston, L., & Galison, P. (2007). Objectivity. Zone Books ; Distributed by the MIT Press.
Deleuze, G., & Guattari, F. (1976). Rhizome: Introduction. Éditions de Minuit.
D’Ignazio, C., & Klein, L. F. (2020). Data feminism. The MIT Press.
Dunbar-Hester, C. (2020). Hacking diversity: The politics of inclusion in open technology cultures. Princeton University Press.
Duran, J. (1991). Toward a feminist epistemology. Rowman & Littlefield.
Foucault, M. (2007). The politics of truth (S. Lotringer, Ed.; L. Hochroth & C. Porter, Trans.). Semiotext(e).
Graham, M., Kitchin, R., Mattern, S., & Shaw, J. (Eds.). (2019). How to run a city like Amazon, and other fables.
Halpern, O., & Mitchell, R. (2022). The smartness mandate. The MIT Press.
Haraway, D. (1988). Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective. Feminist Studies, 14(3), 575. https://doi.org/10.2307/3178066
Haraway, D. (2016). Staying with the trouble: Making kin in the Chthulucene. Duke University Press.
Harding, S. G. (1986). The science question in feminism. Cornell University Press.
Hutchinson, B., Smart, A., Hanna, A., Denton, E., Greer, C., Kjartansson, O., Barnes, P., & Mitchell, M. (2021). Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 560 – 575. https://doi.org/10.1145/3442188.3445918
Joque, J. (2022). Revolutionary mathematics: Artificial intelligence, statistics and the logic of capitalism. Verso.
Juliano, L., & Srinivasan, R. (2012). Tagging it: Considering how ontologies limit the reading of identity. International Journal of Cultural Studies, 15(6), 615 – 627. https://doi.org/10.1177/1367877912451684
Liboiron, M. (2021). Pollution is colonialism. Duke University Press.
Mayer-Schönberger, V., & Cukier, K. (2014). Big data: A revolution that will transform how we live, work, and think (First Mariner Books edition). Mariner Books, Houghton Mifflin Harcourt.
Nadim, T. (2021). Database. In N. B. Thylstrup, D. Agostinho, A. Ring, C. D’Ignazio, & K. Veel (Eds.), Uncertain Archives: Critical Keywords for Big Data (pp. 125 – 132). MIT Press.
Newman, A., Tarasiewicz, M., Wagner, S., & Wuschitz, S. (Eds.). (2016). Openism. Conversations on Open Hardware. University of Applied Arts Vienna in cooperation with the RIAT.
O’Neil, C. (2016). Weapons of math destruction: How big data increases inequality and threatens democracy (First edition). Crown.
Posner, M., & Klein, L. F. (2017). Editor’s Introduction: Data as Media. Feminist Media Histories, 3(3), 1 – 8. https://doi.org/10.1525/fmh.2017.3.3.1
Sinders, C. (2020, May 5). Rethinking Artificial Intelligence through Feminism. CCCB LAB. https://lab.cccb.org/en/rethinking-artificial-intelligence-through-feminism/
Wajcman, J. (2004). TechnoFeminism. Polity.
Wang, A. L.-C. (2003). An industrial-strength audio search algorithm. Proceedings of the 4 Th International Conference on Music Information Retrieval. https://doi.org/10.1.1.217.8882
Acknowledgements
The Negentropic Explorations of Radio research project was generously supported by the SNSF-Spark funding grant number 190310. We are grateful to our research workshops guests: Carl Colena (SIGID wiki), Miro Roman (ETHZ), Simone Conforti (IRCAM), Sarah Grant (Kunsthochschule Kassel) and Roberto Bottazzi (The Bartlett) for their invaluable inputs. Special gratitude goes to Miro Roman for numerous informative discussions on working with SOM, as well as to Carl Colena for his support and discussions on radio signals beyond workshops and interviews. We also want to thank students from Interaction and Game Design of the Zurich University of the Arts and the head of the Physical Computing Lab Paulina Zybinska (ZHDK) for providing important insights discussed in the paper. FHNW Lehrfonds provided invaluable support through funding the Making Arguments with Data teaching project and enabled us to continue this work.
Date received: March 2023
Date accepted: July 2023
1 Colaboratory: browser-based machine learning environment, funded by Google; visit https://colab.research.google.com/ [accessed 15 February 2022].
2 Generative Pre-trained Transformer 3 GPT-3 is one of the language prediction and transformer models released in 2020 by the OpenAI company, which was co-founded by Elon Musk. Read more on GPT-3 here: https://github.com/openai/gpt-3 and https://en.wikipedia.org/wiki/GPT-3; more on OpenAI, https://en.wikipedia.org/wiki/OpenAI
3 CLO Virtual Fashion company founded in 2009 in Seoul, South Korea; https://www.clo3d.com/ [accessed 15 February 2022].
4 Runway ML, machine learning platform for visual tasks; https://runwayml.com/about/ [accessed 15 February 2022].
5 More information on the performance of the dSimon theatre piece in Vidy theatre in Lausanne, in December 2021 is available at: https://vidy.ch/en/dsimon-0 [accessed 15 February 2022].
6 See Anna Ridler’s website for more detail on the artwork Mosaic Virus and related work: http://annaridler.com/mosaic-virus [accessed 10 January 2023].
7 https://mimionuoha.com/the-library-of-missing-datasets as well as in the Github repository of the project: https://github.com/MimiOnuoha/missing-datasets [accessed 10 January 2023].
8 The website of the SIGID wiki is available on http://sigidwiki.com [accessed 19 January 2023].
9 More details on the LAION project and the dataset: https://laion.ai/blog/laion-5b/ [accessed 19 January 2023].
10 Runway ML is a platform offering Video and Image editing and synthesis tools powered by AI and available for a fee https://runwayml.com/ [accessed 20 February 2022].
11 Nomadic is used here to stress the non-settled status of online platforms users, who come and go, register and depart; at the same time, the problem of user uprootedness resonates with Rossi Braidotti’s nomadic theory which addresses nomadic subjects resisting ‘deterritorialization’ in Deleuzian terms (Braidotti, 2011).
12 For an overview on Caroline Sanders’ work see: https://carolinesinders.com/feminist-data-set/ [Accessed 15 February 2022].
13 Google developed Dreambooth, a fine-tuning algorithm for image synthesis algorithms. such tool can be used to include personal images of the user within the model and a have a way to semantically reference to it in the prompt. And while this does to entirely solve the issue of bias in the dataset, it gives an additional tool to correct stereotypical representation. Ruiz, Nataniel, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2022. “DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation.” arXiv. https://doi.org/10.48550/arXiv.2208.12242.
14 More details given at https://laion.ai/about/
15 The SNSF-funded research project Negentropic Explorations of Radio engaged the question of organizing radio signals digital archive. It was running from 2020/21 at the Critical Media Lab, IXDM, Basel Academy of Art and Design. Project documentation is available at https://radioexplorations.ch/. More information on the grant: https://data.snf.ch/grants/grant/190310
16 A ‘fingerprint’ in computational terms is a condensed digital summary of an audio signal, based on peak points in the spectrogram which represent higher energy content. The technique is known for its use in Shazam music identification application (Wang, 2003).
17 We used the free music archive dataset with 8000 samples of music files, representing 8 different genres (Hip-Hop, Pop, Folk, Experimental, Rock, International, Electronic, Instrumental)
18 See more on the signal on its SIGID wiki page: https://www.sigidwiki.com/wiki/CODAR [accessed 20 January 2023].
19 See more on the signal on its SIGID wiki page: https://www.sigidwiki.com/wiki/Glenayre_Paging_Link [accessed 20 January 2023].