
Algorithmic Governmentality, Digital Sovereignty, and Agency Affordances
Extending the Possible Fields of Action
1 Introduction
The car’s on fire and there’s no driver at the wheel […]
We’re trapped in the belly of this horrible machine
(Godspeed You! Black Emperor, 1997)
Almost globally, social lives of individuals are increasingly governed by algorithmic and automated decision-making (ADM) systems. These systems are becoming an inseparable component of our online and offline lives, rendering them a significant actor in shaping socio-processes and dynamics. As indicated by Beer (2017), algorithms participate in a kind of social ordering of the world, having a “constitutive or performative role in ordering that world on our behalf” (p. 4). This can be understood as an agentic power that affects and shapes our communication, social interactions, choices, opportunities, and life chances.
This power to steer behavior, outcomes, and opportunities based on operations of datafication, classifications, ranking, sorting, and predicting leads to what is defined as algorithmic governmentality (Bellanova, 2017; Rouvroy, 2011, 2013; Rouvroy, 2020; Rouvroy et al., 2013; Rouvroy & Berns, 2010; Rouvroy & Stiegler, 2016) or algorithmic governance (Introna, 2016; Katzenbach & Ulbricht, 2019; Latzer & Just, 2017; Latzer & Festic, 2019). Building on the notion of governmentality introduced by Foucault (1991) and further developed by Rouvroy and Berns (2010), algorithmic governmentality implies “government of the social world that is based on the algorithmic processing of big data sets rather than on politics, law, and social norms” (Rouvroy, 2020, para 3). As such, it is a form of (co-) governance that affects the autonomy and agency of individuals, creating power imbalances between them and the opaque systems guiding their lives.
Based on empirical research that relates specifically to platform algorithms, this article discusses the notions and conditions of algorithmic governmentality, which correspond to how things are in terms of limitations on human agency and limits to the ability to control data inputs and algorithmic outputs. In this, we oppose the notion of data and algorithmic sovereignty as a counter-conduct (Foucault, 1991) to algorithmic governmentality, which corresponds to how things ought to be – the ability of individuals to exercise and impose agency, autonomy, and self-determination over algorithmic systems. Finally, we introduce and conceptually operationalize the notion of agency affordances as a tool for algorithmic sovereignty. This should respond to queries regarding how to be algorithmically sovereign and how to extend the possible fields of action.
We approach this by proposing particular solutions and mechanisms, establishing formulations informed by an empirical study and existing theoretical conceptualizations. The empirical research comprises a carefully designed study that sees 47 participants – with the guidance and support of the researchers – request their data from one of eight platforms (Facebook, Google, Instagram, Twitter, Spotify, Netflix, Tinder, or TikTok). To solicit participants’ requirements for agency when interacting with these platform algorithms, based on lived experiences and not in an abstract way, we developed and employed a number of innovative methods and tools. We repurposed the General Data Protection Regulation’s (GDPR) Right of Access (Article 15) to enable participants to access their data, and we used the tool of diary keeping to collect data and capture insights.
In the following chapters, we discuss different notions of algorithmic governmentality before elaborating on the methodology and empirical results. Subsequently, we introduce and discuss the notions of data and algorithmic sovereignty that emerge from our empirical research. Finally, we introduce and conceptually define the notion of agency affordances, finishing with some concluding remarks.
1.1 Algorithmic Governmentality
In an increasingly algorithm-mediated world, many of the everyday practices of individuals are becoming influenced and guided by algorithmic outputs and the decisions made by (machine-learning) algorithms. Ranging from simple content recommendations on social media platforms to decisions concerning medical procedures, insurance policies, and predictive policing, regardless of whether the targets are aware or not, algorithmic workings influence our lives in significant ways (Eubanks, 2018; O’Neil, 2016; McQuillan, 2022).
In a February 1978 lecture later published as Governmentality (1991), Foucault defined governmentality as the “conduct of conducts”, a “form of activity aiming to shape, guide or affect the conduct of some person or persons” (Gordon, 1991, p. 2). This mode of government of “men and things” (Foucault, 1991, p. 94), relies on certain techniques (or technologies) of power, on a series of specific apparatuses, and on power / knowledge and savoir (ibid., p. 103) “designed to observe, monitor, shape and control the behavior of individuals” (Gordon, 1991, p. 2).
According to Foucault (1982), governmentality aims at directing the conduct of individuals and groups, “structure[ing] the possible field of action of others” (p. 791, emphasis ours) by acting on either or both their actions and the possibilities of action. Foucault considers this “mode of action upon the actions of others” (ibid., p.791) an exercise of power. As a complex form of power, governmentality necessitates the assemblage of institutions, procedures, calculations, mechanisms, and tactics of governing in order to steer the conduct of populations and individuals. It is based principally on knowledge (about the governed subjects) and executed via a principal means of various apparatuses (Foucault, 1991, p. 102).
In a series of texts, Antoinette Rouvroy adopts these lenses and introduces the notion of algorithmic governmentality (Rouvroy, 2011, 2013; Rouvroy, 2020; Rouvroy et al., 2013; Rouvroy & Berns, 2010; Rouvroy & Poullet, 2009; Rouvroy & Stiegler, 2016). Algorithmic governmentality is a regime of power (Rouvroy et al., 2013) that can be defined broadly as “a certain type of (a)normative or (a)political rationality founded on the automated collection, aggregation and analysis of big data so as to model, anticipate and pre-emptively affect possible behaviors.” (ibid., p. 10). Resembling Foucault’s conceptualization, two interrelated processes are operating here: the production of knowledge and the exercise of power.
The production of knowledge relies on the process of datafication (van Dijck, 2014), which sees social action transformed into quantified data based on real-time tracking and dataveillance. This knowledge production process is itself called data behaviorism. It relies on data mining and the processing of data based on statistical operations and algorithmic logic in order to produce probabilistic knowledge. The primary aim of this process is to build profiles of individuals, find patterns in their behavior and predict future preferences, attitudes, and behaviors based on those profiles. These are later taken as a basis for directing their actions or to conduct their conduct (Rouvroy, 2013). This knowledge is formed by pure reliance on quantified and stripped-of-context data with no input from the individuals themselves.
However, compared to established knowledge production systems, statistical interpretation of data takes precedence here, with data becoming equivalent to information and knowledge (Rouvroy, 2013, p. 4). In algorithmic knowledge production, a-significant data points (Rouvroy & Stiegler, 2016) – mere signals, stripped of meaning and significance in and of themselves – “function as signs in relation to what they represent” (ibid., p. 8). Hildebrandt (2022) refers to this as “proxy,” where the data points are (mistakenly) understood as a proxy for what they supposedly represent, even if “data is not the same as what it represents, simulates, traces or signals” (p. 3).
Another characteristic of this form of knowledge production is that this knowledge is believed to be readily available in the world, if only enough data could be found and processed. According to Rouvroy (Rouvroy & Stiegler, 2016), this is not produced knowledge in the traditional sense, knowledge about the world, but readily available knowledge, waiting to be discovered in the world. Following Amoore’s (2020) description of algorithms as “aperture instruments” (p. 15), this knowledge is based on selection and the flattening out of the richness of phenomena: instead of totality, just a few aspects are chosen. This prompts a preference for a single interpretation over the many existing other interpretations, which means losing tacit knowledge (Hildebrandt, 2022, p. 8).
This knowledge about governed subjects means that power is exercised through a complex system of procedures, mechanisms, tools, and (knowledge) apparatuses. However, compared to traditional modes of governmentality, there are several differences. First, in terms of how this power is exercised, this is no longer power that uses the physical body or the moral conscience as a vessel (Rouvroy et al., 2013, p. XI). Instead, it operates through the digital profiles assigned to individuals. Second, in terms of who is exercising that power, it is not the state through its institutions, practices, and actors; instead, power is exercised through calculative devices such as algorithmic systems (Introna, 2016, p. 30). Next is the question of how it is affecting individuals. For Rouvroy and Berns (2010), by aiming to structure the possible and limiting the field of action, algorithmic governmentality tries to eradicate the virtual. Because the goal is to minimize uncertainties (of behaviors, actions, outcomes), it aims to restrict possibilities and potentialities.
This aspect is especially important because it concerns the aim and the target of algorithmic governmentality. The aim of algorithmic governmentality is to prevent the actualization of certain potentialities (Rouvroy & Berns, 2010) and to decrease radical uncertainty by affecting potentialities contained within individuals, thus producing probabilistic subjects (Rouvroy, 2013, p. 8). However, this probabilistic subject is not the same as the actual, “experiential, present and sentient subject” (ibid., p.8), and the producing of probabilistic subjects involves “narrowing the ‘aspirational self’” (Reviglio & Agosti, 2020, p. 2) of individuals. In its search for objectivity, security, and certainty (Rouvroy & Stiegler, 2016, p. 12), algorithmic governmentality targets the inactual: that which does not exist or has not happened yet but which is possible and virtual. As such, it touches upon the “unrealized part of the future, the actualization of the virtual” (Rouvroy & Stiegler, 2016, p. 10). It is particularly this contingency, the conditional mode of what individuals could do, that defines agency as such (Rouvroy, 2013) and is being specifically targeted by algorithmic governmentality. By focusing on prediction and pre-emption (ibid.), algorithmic governmentality affects the agency, autonomy, authenticity, self-determination, and self-governance of individuals and, with it, their subjectivity, the ability to account for oneself.
How the domain of subjectivity is affected by algorithmic governmentality is an outcome of the very nature of this mode of governance. The specific type of algorithmic knowledge is hidden, non-accessible, and non-understandable to individuals, precluding them from being able to know and understand how it affects them, effectively eradicating their possibility for self-reflection. This self-reflection is a prerequisite for individual subjectivity. The mode of production of this knowledge, which relies on data behavioralism and takes as an input the “infra-individual data [that] are meaningless on their own” (Rouvroy et al., 2013, p. X), produces “supra-individual models of behaviors or profiles” (ibid.) as output. As such, an algorithmic mode of government produces no subjectification, “circumvent[ing] and avoid[ing] reflexive human subjects” (Rouvroy et al., 2013, p. X).
Within this specific mode of knowledge production individuals are subjected to the process of objectification, their lived experiences first made visible and knowable and then transformed into an object of knowledge (Weiskopf & Hansen, 2022, p. 7). Undergoing this process of subjectivation, understood as the circumvention of reflexivity and self-formation, individuals respond to and potentially internalize prescribed modes of behavior. With this, they transform their relationship with themselves, potentially complying “with what they think and anticipate algorithms or the designers of algorithms are expecting” (Weiskopf & Hansen, 2022, p. 12). This undermines the possibility of individuals giving an account of themselves or “describ[ing] what they are or what they could become” (Rouvroy et al., 2013, p. X). Therefore, to author themselves or to have an authority to “give account of one’s actions meanings” (Rouvroy, 2013, p. 7).
This is not to say that algorithmic systems have absolute power over individuals. As Foucault (1982) states, “power is exercised only over free subjects, and only insofar as they are free” (p. 791), meaning that there are fields of possibilities for behaviors and actions. However, as Gordon (1991) emphasizes, if we understand power to be defined as actions on other’s actions, “it presupposes rather than annuls their capacity as agents; it acts upon, and through, an open set of practical and ethical possibilities” (p. 5). As reflexive subjects, individuals can (continue to) engage in problematizing, disagreeing, questioning, or disobedience (Weiskopf & Hansen, 2022). Although limited, there remain possibilities for refusal, resistance, and repair, spaces for expanding the fields of action.
1.2 Human Agency
In such a constellation, it is worth questioning the position of individuals in relation to their agency. When interacting with or being subjected to the outputs of algorithmic systems, individuals have limited ability to control data flows, to influence algorithmic outputs and act with autonomy, self-reflection, self-directedness, and to self-govern themselves. They have “as-if” or “pseudo” agency. Using the definition provided by Couldry (2014) as a starting point, we understand agency as
not brute acts (of clicking on this button, pressing ‘like’ to this post) but (following Weber) the longer processes of action based on reflection, giving an account of what one has done, even more basically, making sense of the world so as to act within it. (p. 891).
Building our theoretical lens on this and other conceptualizations (Neff & Nagy, 2016; Neff et al., 2012; Nagy & Neff, 2015; Couldry, 2014; Erofeeva, 2019; Feenberg, 2011; Hildebrandt & O’Hara, 2020; Kennedy et al., 2015; Lorusso, 2021; Milan, 2018), we elaborate on several elements related to agency: (1) an ability to act, (2) agency as power, (3) agency as relational, and (4) agency as contextual.
First, agency implies an ability to act. It is an intentional and reflexive practice (Milan, 2018) that enables individuals to reflect on (the technology, their acts, their wishes, their experience, the social world in general) and to act reflectively, with the aim of both adapting to their surroundings and socio-technical contexts (Neff and Nagy, 2016, p. 4916) and impacting them. As such, agency requires the capacity for action, for making choices, and, thus, for breaking automatisms (Lorusso, 2021) when interacting with technological systems.
Second, agency can be understood both as power and as emanating from and immanently implying power relations – as a “capacity, condition, or state of acting or of exerting power” (Lorusso, 2021, para. 3). In a world where we are subjugated to algorithmic power – or as Couldry (20014) would say, where “all agency has now been subsumed by ‘algorithmic power’” (p. 891), the agency to exert one’s own will, to self-govern oneself, should be also seen “in relation to the possibilities for resistance from the margins of power” (Baez, 2002, p. 36).
In that sense, agency is always relational and co-constituted. In our interactions with complex technological systems, there is always a “clash of agencies at play” (Lorusso, 2021, para. 5), and technology and automated decision-making systems significantly contribute to the constitution of human agency (Neff & Nagy, 2016). Agency is not immanently human or technical but is “granted” to a heterogeneity of actors (Bucher, 2018) and emerges in the relationship between them, always in particular circumstances and conditions.
Finally, as such, agency is contextual, particular, and dialogic (Neff & Nagy, 2016, p. 4,925). It is not static, universal, or generalizable, but “it is the ability of social actors to variably engage with and react to the context in which they are embedded that empowers them to change their relation to structure” (Milan, 2018, p. 512). Following Bucher (2018), we might say that agency (of humans and non-humans) emerges from the forces at play within a particular socio-technical assemblage, with each actor’s capacity to act differing depending on the assemblage’s configuration.
2 Methodology
Because of the opaqueness of algorithmic systems, which stems from their complex technical nature, the intentional policies of the companies building and employing them, and the wide network of datafication and data actors, it is exceptionally difficult for individuals to understand how they are entangled in the seemingly ubiquitous datafication and algorithmic infrastructures. This complexity is amplified by the fact that many individuals do not fully know what is happening behind the scenes, and they might lack knowledge about the datafication and curatorial mechanisms (Eslami et al., 2015) or subscribe to various imaginaries about these systems (Bucher, 2017). When soliciting opinions concerning individuals’ needs for increasing their agency in relation to algorithmic systems, these significant methodological challenges introduce potential risks that may distort empirical results.
These risks include the risk that our participants will state their needs based only on abstractions or lack of understanding and the risk that a lack of insight into and knowledge of the modus operandi of the platform algorithms will lead to them stating needs based on incorrect assumptions. Even when individuals do have some comprehension, the limited understanding of concepts entails the risk that they cannot fully grasp the algorithmic mechanics. Additionally, some individuals do not have access to knowledge or cannot afford the considerable time and resources needed to embark on a knowledge-forming journey. Information-accessing and knowledge-seeking are time- and resource-demanding and often require a particular initial set of expertise and skills. In that sense, it can be understood as a privilege. Furthermore, this access to possibilities for knowledge production depends on the place of residence and the applicable regulation – e.g., non-EU individuals cannot enjoy the benefits of the General Data Protection Regulation that already enables some kind of agency in relation to algorithmic systems.
To mitigate this challenge, we designed a methodological setup where our participants will encounter the underlying datafication and algorithmic infrastructure first-hand. Instead of acquiring insights in an abstract way, we designed our study to allow and encourage a purposeful encounter and interaction with the underlying algorithmic infrastructure of each particular platform. The tools and methods were intentionally chosen to enable participants to reflect on the process and formulate and elaborate their insights, thoughts, needs, and requirements based on their experience and interactions. We made particular arrangements to provide guided support throughout the study.
The study design takes the form of multi-stage participatory research with 47 participants during a three-month period in 2020. The stages included completing a survey, filing a Subject Access Request (SAR) (according to Article 15) (European Commission, 2016), and purposeful interacting with the transparency tools made available by the platforms, which allow users to access information about themselves and their data (e.g., inferences, advertisements delivered, location data collected). A structured diary template comprising 15 questions was provided to participants with the aim of both recording their interactions (and also their thoughts) and enabling a reflexive process of understanding and producing knowledge about and around those interactions. Each diary follows the process of “getting to know” the algorithmic system of the platform chosen by the participant and interacting with the system to detect what it is that they have been given access to and what knowledge they are “afforded” and how. As such, the diary facilitated critical knowledge and reflexivity about both the algorithmic systems and oneself, insights that would not be otherwise accessible (Fisher, 2020).
Figure 1:Overview of the Methodological Design and Study Outputs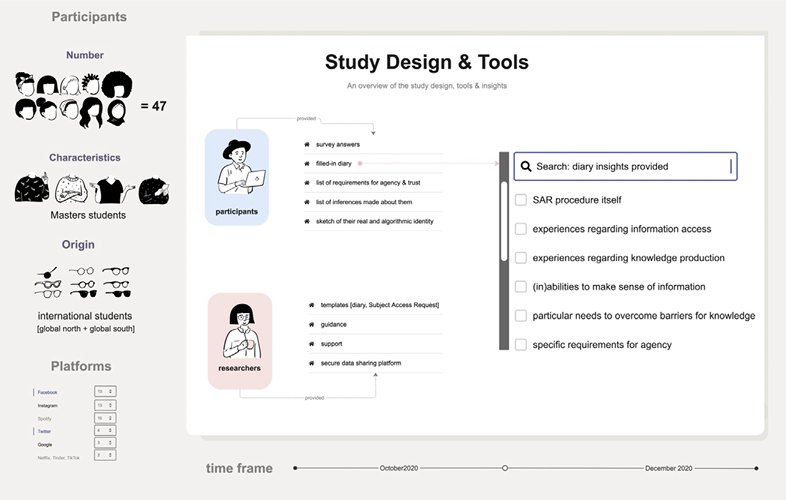
The first-hand experience prompted reflection about the power relations between the participants and the platforms, which tacitly included their abilities to act or not act and to have agency – to self-govern themselves and have control over their self-representation. This led them to become aware of what they needed. Following Tkacz et al. (2021), we also view our (algorithmic) diaries as both a process and a product: a process of discovery, reflection, and ultimately, growth. Furthermore, as a product, each diary is one totality in itself that enables us, the researchers, to approach it as a study object to be analyzed and used for insights.
The study participants were all international students in an English-taught master’s program taking a course at the university where the authors work. This meant that it was the first time that many of the students had the opportunity to exercise their data protection rights because they had come from non-EU countries where there is no data protection regulation, and the General Data Protection Regulation does not apply. An unpublished report from our survey shows that 77 % of our participants had never submitted a SAR before. However, because this course concerned questions of data, privacy, and digital (communication) technologies, it is to be presumed that most already had some interest in and maybe even pre-existing knowledge of the topic.
Due to the possibility of de-identifying individuals, no demographic data was requested. We contend that the need to minimize the risk of potential re-identification of the participants outweighs the potential benefits of collecting demographic data. Additionally, for the insights we sought, demographic data was of no significance. To secure pseudonymization, the participants were provided with a unique code, and the documents we received were labeled with this code.
Regarding the choice of platforms, we instructed participants to choose between one of eight platforms: either Facebook, Google, Instagram, Twitter, Spotify, Netflix, Tinder, or TikTok. The first of several reasons for this is obvious: Because these are the biggest platforms, we expected each participant to have an account with at least one of them and probably to have maintained that account for a substantial period. One criterion for choosing a platform was for the participants to already have an account, ensuring that profiling and data collection had already been taking place for some time. The second reason concerns regulation compliance: We expected these platforms to be the most compliant with Article 15 and to have well-established procedures and accessible transparency tools. Finally, we pre-tested the SAR and transparency processes of all these platforms to be able to offer guidance and support to our participants during the course of the study where necessary.
At the end of the process, the participants provided 1) a list of all the inferences assigned to them by the platform of their choice, 2) a list of their requirements for a) agency and b) trust, 3) a drawing of their real identity (based on their own understanding of themselves) and their algorithmic identity (based on their “reading” of the inferences of their platform), and 4) their completed diary.
3 Results
3.1 Against Governmentality –
Sovereignty as a Mode of Counter-Conduct
Taken in their entirety, the diaries enable us to observe not only how this algorithmic governmentality operates in terms of its mechanisms, practices, actors, and knowledge but also how it was experienced by our participants. It also enabled us to see the performative outcomes of these governing practices (Introna, 2016,) and how the conduct of conduct (Foucault, 1991) unfolded and limited the possible fields of action of our participants (Foucault, 1982). Our participants reported feelings of having no control over their data or the algorithmic outputs, no ability to disagree or refuse, no autonomy over their own (algorithmic) identity, no venue for exercising authenticity, and no outlet for self-determination.
However, we could also identify a counterpoint. Specifically investigating participants’ requirements for agency enabled identification of possible modes of counter-conduct against this algorithmic governmentality. After recording all the participant entries under “requests for agency” in the diary, a total of 159 requirements were coded using the framework for thematic analysis (Braun & Clarke, 2006). Our analysis shows that agency requires that three preconditions be met: the ability to see, the ability to understand, and the ability to act (see Figure 2).
Figure 2: Coded Requests for Agency
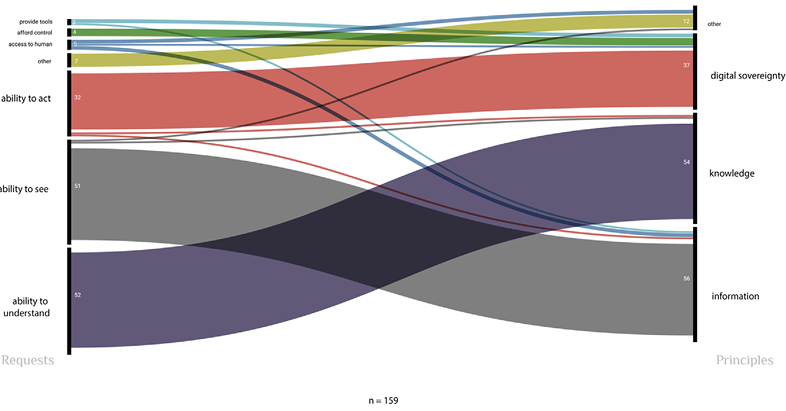
The ability to act constitutes what we call digital sovereignty, which takes the distinct but interrelated forms of data sovereignty and algorithmic sovereignty. Meanwhile, digital sovereignty is inextricably linked to the ability to see and the ability to understand. Here, we see what Foucault calls power/knowledge: To be able to govern (oneself), to be a sovereign (of oneself), one needs to possess knowledge, and to possess the knowledge, one needs to first have access to information for knowledge-making.
Before we more closely consider these two distinct forms of sovereignty requested and their relationship with knowledge-making, it is worth briefly discussing the use of the notion of sovereignty here. For Pohle and Thiel (2020), digital sovereignty emerges as a separate category of sovereignty that emphasizes the autonomy of the user and the individual’s self-determination in relation to digital systems and technologies (p. 59). No longer exclusively understood in relation to nation-states, sovereignty is conceived of as the ability of individuals “to take actions and decisions in a conscious, deliberate and independent manner” (ibid.). Distancing the concept from the original characteristics of the sovereign as having authority over a territory (Couture & Toupin, 2019, p. 2,318) but continuing to build on it, Roio (2018) claims that the digital dimension does, in fact, constitute a territory, but a territory of governing the individual. This refers not to governance over the physical bodies of individuals but to governance over the algorithmically produced inferences about them (see also Rouvroy & Berns, 2013). However, this governing of the digital spills into the territory of the real because it affects and often influences the prospects and lives of real individuals (see Eubanks, 2018).
Figure 3: Requests According to Frequency and Type of Sovereignty
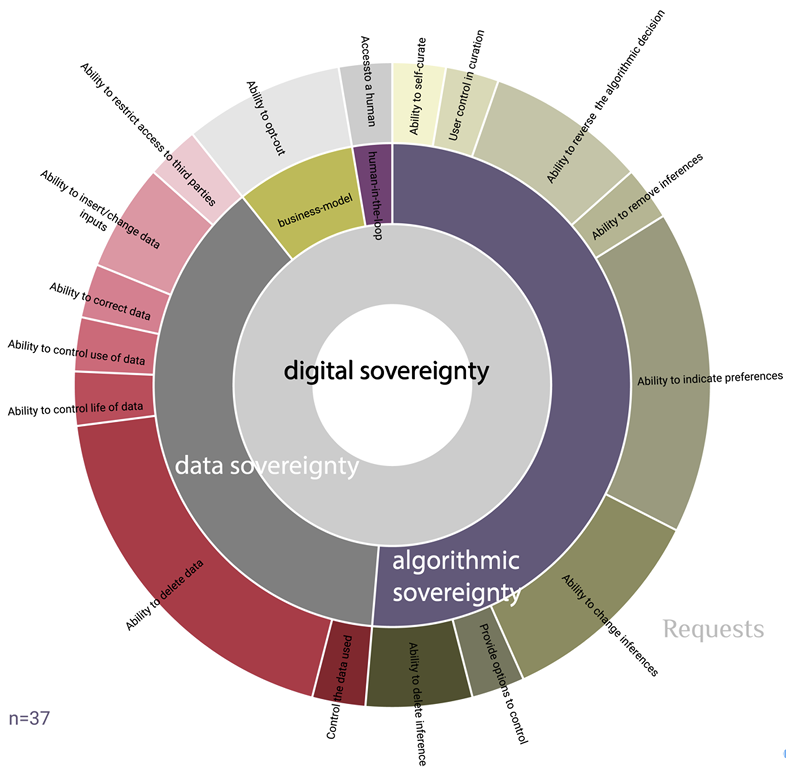
As the responses make evident, this request for sovereignty is understood as an ability to act, which refers to first making an autonomous and authentic decision and then, consequently, acting upon it. It pertains to very tangible requests related to both the data and the algorithmic outputs. Being very particular, we categorize these requests into the two distinct but interrelated categories of data sovereignty and algorithmic sovereignty. Digital sovereignty is tightly related to the elements of control, autonomy, authority, self-reflection, and self-determination. Being able to act and make decisions autonomously should enable not only self-directedness but also the ability to realize and perform one’s own subjectivity and identity, in short, to act agentially.
Data Sovereignty
Abilities to act in relation to data concern data during all phases of the data cycle: data design, data capture, data processing, and data usage (see Figure 3). The most frequent request is to be able to delete data. This ranges from the deletion of the data held by a particular actor / digital platform to the deletion of the inferences made based on that primary data. This extends to data held by third parties. This request is related, and closely followed by frequency, to the request to insert / change data inputs, which points to the need to be able to make an autonomous decision that will correspond to the wishes of the individual regarding what data is collected and how to correct it if, for example, it is deemed sensitive or incorrect. All these requests relate to the ability to control the data collection, the actors collecting the data, the purposes of use, the use of the data itself, and the data life cycle.
This demonstrates that many participants relate their ability to act to being able to control both the data provenance – what data is collected, how, and by whom – and the data cycle – how the data is shared, with whom, what it is used for, and how. This extends to the ability to change, modify, delete, and opt-out. Hummel et al. (2018, also 2021) define data sovereignty as having and exercising meaningful control – including via ownership of data and data infrastructures – to “govern informational resources” (p. 10). Building on this, we see that our participants framed data sovereignty as autonomy through authority, authenticity, and self-reflection. This autonomy represents an ability to act intentionally by articulating one’s wishes and doing as one pleases without external inferences (Hummel et al., 2021), which means being able to challenge, oppose, and reject.
Algorithmic Sovereignty
The requests that we categorized under algorithmic sovereignty concern the outputs of the algorithmic processing of the data from and about the individuals (Figure 3). This type of sovereignty envisions having power over algorithms and their outputs that govern not only individual’s digital profiles but also (often) offline lives. As such, it describes an ability to claim authority over these outputs and the process of subjectification, an antidote to the algorithmic steering of life chances, the algorithmic conduct of conducts. This resembles the notion of algorithmic sovereignty as defined by Reviglio and Agosti (2020) as well as Roio (2018): an ability and possibility of individuals to have meaningful control over the workings and outputs of algorithmic systems, to be able to impose their autonomy and wishes, and to achieve authenticity leading to self-directedness. Understood as such, it relates to several important dimensions of sovereignty: control, power, and authenticity.
Regarding the element of authenticity, as the analysis demonstrates, the most prominent requests concern the abilities of individuals to indicate preferences themselves. In essence, this refers to a request to be able to self-author oneself, to give an account of oneself, or, as mentioned, to describe “what they are or what they could become” (Rouvroy et al., 2013, p. X). This grants individuals the authority to define themselves and the ability to impose their own way of seeing themselves and their authenticity, which stands in opposition to what systems assign to them as their interests, wishes, and needs. Such an authority will eradicate the limitations on the possibilities for action imposed by algorithmic reasoning and enable the potential actualization of virtualities.
This request is followed by – and relates to – the ability to change the already algorithmically constructed inferences. Being able to change something that is seen as incorrect or sensitive, as no longer applicable or representative of the individual, or simply as not aligning with the individual’s wishes, gives them control over the algorithmic outputs that later steer and impact their behaviors, actions, and practices. This control also means having not only power to delete, change, restrict, refuse, and repair but also power over algorithmic systems.
This power over exhibits itself as self-directedness and is apparent in the request to be able to reverse an algorithmic decision, which captures the possibility of disagreeing with the algorithmic output, rejecting it, and purposefully changing the outcome. In essence, it describes a request by participants to resist algorithmic governmentality and actively govern their own lives.
As recognized earlier, these autonomous decisions in relation to both the individual data and the algorithmic outputs impacting them are foregrounded on two related elements: the ability to gain and form knowledge, which, in turn, is enabled by the ability to see (for themselves), to receive information. These abilities (Figure 2) are preconditions for the ability to act and to exercise power over algorithmic systems, which engenders power over oneself to be digitally sovereign.
3.2 Reclaiming Power/Knowledge
As briefly discussed in reference to Foucault’s notion of power/knowledge, access to the knowledge held by digital platforms represents a counterpoint to algorithmic reasoning and data behaviorism. This flipping of the epistemic script can and is a productive and positive force, because accessing the knowledge that particular algorithmic systems produce and hold about an individual can open up spaces for disagreement, refusal, and change.
As the analysis also demonstrates, this takes the form of both access to information and the ability to understand or form knowledge, exceptionally important concepts because they should help individuals overcome epistemic imbalances to some extent. Making visible the inner workings of systems opens them up for understanding and knowledge production. Although insufficient in itself for acting agentially – an idea to be elaborated further – the opportunity to understand, reflect, and decide based on that is fundamental. Knowledge precedes agency, and in our view, knowledge is only relevant if it generates, and if it is coupled with, the ability to act. To (re)gain agency, individuals must know and be able to understand how the algorithmic systems governing them work. Knowing and understanding, but not being able to disagree, oppose, correct, change, or in any way interact and impose some autonomy over the system strips individuals of their agentic power over these systems.
However, knowledge cannot be formed if no information is provided. For this reason, the primary request is the ability to see, which captures the ability to access, to be presented with, and to receive information (Figure 3). Concretely, this refers to seeing for oneself how one is positioned within the broad datafication and algorithmic systems, including the actors in the datafication network that provide, receive, and use the data collected (e.g., data brokers and advertisers). The analysis of the requests makes it apparent that this is a baseline requirement that should be introduced at an interface level.
Figure 4: Requests According to Frequency and Principles

Requests relating to information access can be classified into two categories: data provenance & cycle transparency and information structuring & access.
Data provenance and cycle transparency mostly concern information concerning data origin and usage: with whom data is shared, what is considered data, what/who is the source of the data, what data is collected, and how and where is it stored. This information pertains to the data ecosystem, which includes third parties with access to or who share data, data sources, identification of data collectors and data processors (including inference sources), and information about when something becomes data.
Information structuring and access concern requests to make information either or both more visible and more understandable. These requests pertain to better information structuring, making information simpler and easier to understand, presenting information clearly, and making it easily accessible via the interface. For example, numerous respondents also demanded more accessible policies written in simpler language. The struggle to navigate the process of accessing their data, as reported by our participants, could be remedied by interface solutions (e.g., more user-friendly interfaces and navigation maps) and by making tools discoverable.
However, in and of itself, information is not enough. Providing all the information that users require does not necessarily engender agency: Even if information asymmetry is corrected, knowledge and power imbalances are not. This is because the ability to make sense of these data and that information continues to be contained within the platforms themselves. Users have been stripped of the possibility of understanding by being deprived of the key elements required to know how to read the data that they have been provided with.
As such, the second major request relates to the ability to understand / knowledge. This is an ability for sense-making and understanding. If access to information constitutes the baseline for making things visible and known, this request concerns making things knowable and having opportunities and tools to understand and comprehend. Several participants made apparent that they want to be able to understand the algorithmic process in its entirety, which includes how it affects them, their behavior, their personhood, and their future.
Put simply, often the data provided to individuals based on their SAR or through transparency tools are raw data. This is information – data is being provided. However, such data can be presented either in “legalese,” that is, using difficult legal terms, or in a format unfamiliar to a layperson (e.g., JSON) with no further explanation. This points to knowability – providing information and explanations in a way that enables sense-making and understanding.
According to our analysis, when it comes to knowability, the most prevalent request is for knowledge concerning how automated decisions are made (mentioned by 68 % of participants). This ranges from broader questions about the algorithm’s design to more concrete questions about why users are presented with certain content in their feed or what particular data points produce certain inferences. How inferences about them are made seems particularly important – knowledge is required regarding what user actions lead to what inferences and how categorizations are made and by whom.
There are, however, also requests about making this inquiry easy to understand. According to our participants, this could be achieved using educational material. Such material might be introduced at various stages of platform use and might take forms ranging from tutorials and walkthroughs to tick boxes and special training content, including videos.
3.3 Agency Affordances as Tools for Counter-Conduct
This section contemplates translating these requirements and securing actualization of control, autonomy, authenticity, and sovereignty in relation to algorithmic systems. We build on the notion of affordances to propose the notion of agency affordances, which we define as functions programmed at an infrastructure level that should allow and encourage the actualization of agency via the introduction of features and elements that are made visible and promoted at an interface level. This should couple the possibilities for action with the ability to act. In doing so, agency affordances should enable self-directedness, self-reflection, and self-governance. However, the existence of affordances and the possibilities of particular actions do not guarantee that an action is executed. Affordances are complex, dependent on a multitude of factors. The implementation of agency affordances requires introducing functions and features at the level of technological artifact as well as supporting dynamics and conditions that transcend the technical. The later should be requested, enabled, and encouraged via societal (infra)structures, such as regulations, institutions, and organizations.
The following section briefly outlines the most important aspects of affordances in general. Subsequently, we discuss how they should be implemented based on the requirements of our participants and our analysis. Finally, we provide examples of agency affordances.
While we acknowledge the complexity of the task of defining the concept of affordances, we also outline characteristics essential for the concept of agency affordances. Agency affordances are non-determining, relational, dynamic, context-dependent, situated, and arrive in gradations and variability. Affordances refer to “the range of functions and constraints that an object provides for, and places upon, structurally situated subjects” (Davis & Chouinard, 2017, p.1). However, affordances do not determine the “possibilities for agentic action in relation to a subject” (Hutchby, 2001, p. 444). Instead, they exist in an in-between space where the possibilities for action might or might not materialize, a space dependent on both the context and the circumstances of the individual. As such, the presence of affordances does not, by default, result in certain behaviors but merely indicates that they “contribute to the (recognizable) possibility of that activity” (Neff & Nagy, 2015, p. 3).
Affordances relate intrinsically to agency, but this does not necessarily mean that they allow for agency to be actualized by default. Affordances not only encourage but also limit, discourage, and completely refuse particular lines of action by significantly shaping what is possible and doable. For example, as the empirical results revealed, platform algorithms limit the abilities to control the collection of data while allowing access to the data the platform holds. This means that technological artifacts also shape human agency and the ability of individuals to act and determine the conditions and the ways in which agency emerges, when and how, and for whom (and whom not). For example, the ability to read and understand JSON files will disproportionately affect individuals that do not know how to open or read the format.
Several authors have emphasized the need to shift the focus from what affordances afford to how they afford, for whom and under what circumstances (Davis, 2020), including when agency is mobilized and on whose behalf (i.e., individuals or algorithms) (Bucher, 2018). As already discussed, “pseudo” or “passive” agency is often already afforded to individuals by the platforms, but this is not an active, meaningful, or productive kind of agency. It is an agency that is somewhat allowed (Davis, 2020), with individuals nudged in a particular direction without a real ability to know, inspect, learn, and act independently and autonomously in a self-determining and sovereign manner.
This somewhat-allowed agency is possible and actualized to varying degrees and at different gradations. As both Davis (2020) and Evans et al. (2017) recognize, by working in gradations, affordances allow certain lines of action to some and discourage the very same lines of action for others. In such instances, the action is available “but not readily so” (Davis, 2020, p. 114). Some individuals must overcome obstacles, and the action requires extra effort or technical savviness, assuming that the individuals have the material (e.g., tools) and immaterial (i.e., knowledge and skills) resources and abilities to begin with. This renders these actions “effortful and deliberate” (Davis, 2020, p. 122), something that our study results also reveal. More tech-savvy participants could more easily navigate technical constraints. Those who were not often asked us, the researchers, for guidance and assistance.
Because platform algorithms are part of socio-technical assemblages, they are always embedded in the momentary enactments, positionings, and repositionings of social and technical elements in relation to each other (Dahlman et al., 2021). This implies that we must also account for the inevitable entanglement of actors, elements, and (infra)structures, which captures laws, regulations, institutions, societal contexts, and the particularities of individuals and their situatedness within systems. This is also important for discussing how agency affordances should be enabled and how their actualization should be supported.
Enabling Agency at an Artifact Level
The complex issue with affordances and the difficulty of their embedment in technological artifacts is that they are not properties of the artifact itself and nor are they a feature. They are relational, meaning that they exist as a possible outcome and emerge from the interactions of users with the object (Evans, 2017). Affordances can be enabled by introducing particular features and enabling certain conditions to allow for and encourage the actualization of the individual’s agency in interactions with the given algorithmic system. By working together, these features and conditions should enable varying degrees of agential actions and the actualization of different and multiple outcomes. These outcomes will always arrive in gradations that depend on the willingness of individuals to know and understand, on their cognitive capacities, on time constraints and circumstances, and on technical and societal barriers. However, the aim is to design these features and conditions to ensure that such constraints are mitigated, producing equal opportunities to achieve the same level of agency. The following section discusses the ways that this could be achieved.
First, the affordance of discoverability allows individuals to locate features that enable them to act agentially. Not a feature in itself, discoverability emerges from various elements and features that can be embedded in the artifact’s design, including tabs, buttons, pop-ups, and occasional reminders. Some of the remarks and requirements of our respondents revolved around the ability to locate such features. They often asked for accessible options and tools, such as easy-to-toggle on-off settings and preferences, buttons, and widgets. To make something discoverable involves also making it perceivable. For our participants, that would mean making the features, tools, and mechanisms that enable agency easy to identify or “visible.” For example, it would be possible to construct a distinct and clearly visible tab on the home screen for individuals to access all of their data (instead of hiding access in the settings area). This will also make the process less labor-intensive. Even if not every individual used the feature, its availability would be known and perceptible. Making something perceptible and recognizable is a necessary condition for action and agency (Davis & Chouinard, 2017, p. 5). Knowing about a feature’s availability – which includes what it is, how it can be used, and what it can be used for – is crucial for being able to actualize affordances. If an individual is unaware of an artifact’s possibilities, “the artifact refuses the lines of action that the feature enables” (Davis & Chouinard, 2017, p. 5).
As such, these elements, features, and functions affording agential actions should also all be accessible for everyone. They should enable various outcomes, to various degrees, for a variety of individuals depending on their context, circumstances, abilities, and needs. For example, our participants requested privacy policies, terms of service, and settings written in clear, understandable language and adjusted to their individual needs and specific cognitive capacities. Accessibility of information and knowledge could also mean providing information in different formats (e.g., JSON for some, Excel for others) or introducing educational videos, visualizations, tutorials, and educational pop-ups.
The introduction of friction through various functions and features could also enable more agential behavior. By consciously interrupting behavior and introducing laborious decisions (Lorusso, 2021), friction can encourage and facilitate awareness of what is happening “in the background.” Coupling this with the introduction of “stop and think” points should encourage more thoughtful and agential interaction. In this sense, establishing the system as seamful and opening it up to render its elements, workings, and outputs visible and apparent (Schraefel et al., 2020; Couldry & Mejias, 2019; Veale & Delacroix, 2020) produces opportunities to understand algorithmic processes.
However, none of this will matter if these affordances do not allow for executability or actionability. It is crucial to make agency actionable and implementable. For example, although users can see how they have been profiled, the current systems offer no way for them to disagree, reject, refuse, or repair these inferences. Elsewhere, although the opportunity exists for a user to file an SAR, the process itself is laborious, opaque, and (for many) incomprehensible, effectively discouraging individuals from exercising their rights and, by extension, agency.
These represent just a handful of illustrative examples – our aim is not to prescribe formulas. Programming and introducing agency affordances require various actors, processes, infrastructures, and institutions to come together at various levels, both before and after the development and employment of AI systems. Each system will be different, each context will be specific, and each actualization will have its own characteristics. Making agency affordances operational will require thoughtful development and planning, at the level of both infrastructure and interface as well as beyond the technical and towards the institutional and societal levels.
Agency Affordances Beyond Interface and Infrastructure
If enabling agency affordances is the most important step, we must transcend the technological to make agency possible and doable. Being relational and robust, agency and affordances are part of correspond to a larger socio-technical assemblage of actors, artifacts, institutions, and dynamics. Here, we focus on what we think are the most important factors. First, private and public entities and institutions should enable and encourage the development of skills, knowledge, and literacy. Second, regulatory bodies and institutions should establish institutional norms for enabling agency affordances. Third, individuals should be willing – and equipped with the necessary skills – to actualize agency affordances. This will require the coming together of many actors, and only through cooperative responsibility (Helberger et al., 2018) can an empowering dynamic between algorithmic systems and individuals be ensured.
Regarding the ability of individuals to actualize agency affordances, we are building further on the conditions for affordances framework (Davis, 2020), which identifies dexterity as a condition. For Davis (2020), dexterity describes “the capacity of the subject to enact the functions of an object” (p. 144). Dexterity includes the capacity to deploy a feature (Davis & Chouinard, 2017, p. 5) but also transcends simple capacities. Capacities can be physical or cognitive (David, 2020). Physical capacities imply that an individual must be physically in a position and able to manipulate an artifact. This means that we need two actors and elements: the individual’s ability and the material presence or visibility of the feature making known that it can be utilized. The cognitive ability to harness the mechanics of an affordance and to know what a certain feature implies and what its effects are requires knowledge, the ability to put that knowledge to use, and (often) a particular skill set. This all transcends what is offered by the artifact and concerns the wider social context. As our results demonstrate, the ability to know is one of the three main requirements for agency. This knowledge should arrive from at least two sides: the platforms themselves and the broader societal environment. The platforms could enable knowledge acquisition via, for example, tutorials, guidelines, educational videos, and explanatory tools. The broader societal structures could establish the foundation for knowledge through digital literacy initiatives that focus on data and algorithmic literacy and emphasize the significance of agency when interacting with algorithmic systems (see, e.g., data infrastructure literacy; cf. Gray et al., 2018). Such initiatives do not exempt platforms from doing their part.
Regulation should also help program and make agency affordances operational “on the ground.” We contend that only if the enabling of agency affordances is made mandatory can we move beyond the “good will” of companies and platforms. Cultural and institutional legitimacy plays a role in the actualization of agency affordances (Davis, 2020; Davis & Chouinard, 2017). This means that the existence of not only particular laws and regulations but also norms and values inform and guide human-technology relations. Instituting agency affordances as mandatory via regulations will not only impose agency by default and design.” It will also contribute to fostering skill development (e.g., through mandatory educational materials provided by platforms). In principle, this could ensure equity for every individual, no matter their position within the larger socio-technical system (e.g., less data-literate individuals will be equally as protected as highly data-literate individuals).
4 Conclusion
Being governed by algorithmic devices through a specific mode of algorithmic governmentality significantly impacts the online and offline lives of individuals. By aiming at eradicating uncertainty, containing and limiting virtuality, and structuring fields of possible actions of individuals by building probabilistic knowledge, algorithmic governmentality represents a complex form of power over or control of individuals and populations. However, this article aims to demonstrate that “another future” is both demanded and possible. Our empirical research allows us to position the notion of digital sovereignty as an antidote to algorithmic governmentality. Capturing elements of agency, control, autonomy, authority, self-reflection, and self-determination, digital sovereignty implies self-directedness as well as the ability to realize and perform one’s own subjectivity and identity. Additionally, enabling and encouraging digital sovereignty allows for fundamental disagreement, questioning, refusal, and repair.
We introduced agency affordances via tools that should enable the expansion of the space and the fields of (counter-)actions of individuals in relation to algorithmic systems. Understood as “a form of power” (Neff & Nagy, 2015, p. 4), agency affordances matter. What is being afforded, how, and to whom reveals not only power imbalances but also the power to define how artifacts can be used and to whose benefit. Analyzing affordances reveals the underlying politics and norms programmed and enacted and how they reinforce power structures and imbalances.
Although we conceptualized and provided several illustrative examples of what these agency affordances entail, their implementation would ultimately require collaboration between various actors at different levels, from technology design to regulation. With this article, we hope to have offered different perspectives on individual agency and possible paths toward digital sovereignty.
References
Amoore, L. (2020). Cloud ethics: Algorithms and the attributes of ourselves and others. Duke University Press.
Aradau, C., & Blanke, T. (2022). Introduction. In C. Aradau & T. Blanke (Eds.), Algorithmic reason: The new government of self and other (p. 0). Oxford University Press. https://doi.org/10.1093/oso/9780192859624.003.0001
Baez, B. (2002). Confidentiality in qualitative research: Reflections on secrets, power and agency. Qualitative Research, 2(1), 35 – 58.
https://doi.org/10.1177/1468794102002001638
Beer, D. (2009). Power through the algorithm? Participatory web cultures and the technological unconscious. New Media & Society, 11(6), 985 – 1002. https://doi.org/10.1177/1461444809336551
Beer, D. (2017). The social power of algorithms. Information, Communication & Society, 20(1), 1 – 13. https://doi.org/10.1080/1369118X.2016.1216147
Bellanova, R. (2017). Digital, politics, and algorithms: Governing digital data through the lens of data protection. European Journal of Social Theory, 20(3), 329 – 347. https://doi.org/10.1177/1368431016679167
Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology.
Qualitative Research in Psychology, 3(2), 77 – 101.
https://doi.org/10.1191/1478088706qp063oa
Bucher, T. (2017). The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1), 30 – 44. https://doi.org/10.1080/1369118X.2016.1154086
Bucher, T. (2018). If...Then: Algorithmic power and politics. Oxford University Press. https://doi.org/10.1093/oso/9780190493028.001.0001
Bucher, T., & Helmond, A. (2018). The affordances of social media platforms. In The SAGE Handbook of Social Media (pp. 233 – 253). Sage Publications. https://dare.uva.nl/search?identifier=149a9089-49a4-454c-b935-a6ea7f2d8986
Costa, E. (2018). Affordances-in-practice: An ethnographic critique of social media logic and context collapse. New Media & Society, 20(10), 3641 – 3656. https://doi.org/10.1177/1461444818756290
Couldry, N. (2014). Inaugural: A necessary disenchantment: Myth, agency and injustice in a digital world. The Sociological Review, 62(4), 880 – 897.
https://doi.org/10.1111/1467-954X.12158
Couture, S., & Toupin, S. (2019). What does the notion of “sovereignty” mean when referring to the digital? New Media & Society, 21(10), 2305 – 2322. https://doi.org/10.1177/1461444819865984
Dahlman, S., Gulbrandsen, I. T., & Just, S. N. (2021). Algorithms as
organizational figuration: The sociotechnical arrangements of a fintech start-up. Big Data & Society, 8(1), 20539517211026704.
https://doi.org/10.1177/20539517211026702
Davis, J. L. (2020). How artifacts afford: The power and politics of everyday things. MIT Press.
Davis, J. L., & Chouinard, J. B. (2017). Theorizing affordances: From request to refuse. Bulletin of Science, Technology & Society, 36(4), 241 – 248.
https://doi.org/10.1177/0270467617714944
Delacroix, S., & Veale, M. (2020). Smart technologies and our sense of self: Going beyond epistemic counter-profiling. In M. Hildebrandt & K. O’Hara (Eds.), Life and the law in the era of data-driven agency (pp. 80 – 99). Edward Elgar Publishing. https://www.elgaronline.com/view/edcoll/9781788971997/9781788971997.00011.xml
Erofeeva, M. (2019). On multiple agencies: When do things matter?
Information, Communication & Society, 22(5), 590 – 604.
https://doi.org/10.1080/1369118X.2019.1566486
Eslami, M., Rickman, A., Vaccaro, K., Aleyasen, A., Vuong, A., Karahalios, K., Hamilton, K., & Sandvig, C. (2015). “I always assumed that I wasn’t really that close to [her]”: Reasoning about invisible algorithms in news feeds. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, 153 – 162.
https://doi.org/10.1145/2702123.2702556
Ettlinger, N. (2018). Algorithmic affordances for productive resistance.
Big Data & Society, 5(1), 2053951718771399.
https://doi.org/10.1177/2053951718771399
Eubanks, V. (2018). Automating inequality: How high-tech tools profile, police, and punish the poor. St. Martin’s Publishing Group.
Evans, S. K., Pearce, K. E., Vitak, J., & Treem, J. W. (2017). Explicating affordances: A conceptual framework for understanding affordances in communication research. Journal of Computer-Mediated Communication, 22(1), 35 – 52. https://doi.org/10.1111/jcc4.12180
Feenberg, A. (2017). Agency and citizenship in a technological society. In Spaces for the Future (1st ed., pp. 98 – 107). Routledge.
https://doi.org/10.4324/9780203735657-10
Fisher, E. (2020). The ledger and the diary: Algorithmic knowledge and subjectivity. Continuum, 34(3), 378 – 397.
https://doi.org/10.1080/10304312.2020.1717445
Foucault, M. (1982). The subject and power. Critical Inquiry, 8(4), 777 – 795.
Foucault, M. (1984). The Foucault Reader (P. Rabinow, Ed.). Pantheon Books.
Foucault, M. (1991). Governmentality. In G. Burchell, C. Gordon, & P. Miller (Eds.), The Foucault effect: Studies in governmentality (pp. 87 – 105). University of Chicago Press. https://press.uchicago.edu/ucp/books/book/chicago/F/bo3684463.html
Gibson, J. J. (1979). The ecological approach to visual perception. Houghton Mifflin.
Gordon, C. (1991). Governmental rationality: An introduction. In G. Burchell & P. Miller (Eds.), The Foucault effect: Studies in governmentality (pp. 1 – 53). University of Chicago Press. https://press.uchicago.edu/ucp/books/book/chicago/F/bo3684463.html
Gray, J., Gerlitz, C., & Bounegru, L. (2018). Data infrastructure literacy. Big Data & Society, 5(2), 2053951718786316. https://doi.org/10.1177/2053951718786316
European Commission. (2016). Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). https://eur-lex.europa.eu/eli/reg/2016/679/oj
Helberger, N., Pierson, J., & Poell, T. (2018). Governing online platforms: From contested to cooperative responsibility. The Information Society, 34(1), 1 – 14. https://doi.org/10.1080/01972243.2017.1391913
Herlo, B., Irrgang, D., Joost, G., & Unteidig, A. (Eds.). (2021). Practicing sovereignty: Digital involvement in times of crises. transcript Verlag.
https://doi.org/10.14361/9783839457603
Hildebrandt, M. (2022). The issue of proxies and choice architectures. Why EU law matters for recommender systems. Frontiers in Artificial Intelligence, 5. https://www.frontiersin.org/article/10.3389/frai.2022.789076
Hildebrandt, M., & O’Hara, K. (2020). Introduction: Life and the law in the era of data-driven agency. In M. Hildebrandt & K. O’Hara (Eds.), Life and the law in the era of data-driven agency (pp. 1 – 15). Edward Elgar Publishing. https://www.elgaronline.com/view/edcoll/9781788971997/9781788971997.00006.xml
Hummel, P., Braun, M., Augsberg, S., & Dabrock, P. (2018). Sovereignty and data sharing. ITU Journal: ICT Discoveries, 1(2).
https://www.itu.int:443/en/journal/002/Pages/11.aspx
Hummel, P., Braun, M., Tretter, M., & Dabrock, P. (2021). Data sovereignty: A review. Big Data & Society, 8(1), 2053951720982012.
https://doi.org/10.1177/2053951720982012
Hutchby, I. (2001). Technologies, texts and affordances. Sociology, 35(2), 441 – 456. https://doi.org/10.1017/S0038038501000219
Introna, L. D. (2016). Algorithms, governance, and governmentality: On governing academic writing. Science, Technology, & Human Values, 41(1), 17 – 49.
Just, N., & Latzer, M. (2017). Governance by algorithms: Reality construction by algorithmic selection on the Internet. Media, Culture & Society, 39(2), 238 – 258. https://doi.org/10.1177/0163443716643157
Katzenbach, C., & Ulbricht, L. (2019). Algorithmic governance.
Internet Policy Review, 8(4).
https://policyreview.info/concepts/algorithmic-governance
Kennedy, H., Poell, T., & van Dijck, J. (2015). Data and agency.
Big Data & Society, 2(2), 2053951715621569.
https://doi.org/10.1177/2053951715621569
Lash, S. (2007). Power after hegemony: Cultural studies in mutation?
Theory, Culture & Society, 24(3), 55 – 78.
https://doi.org/10.1177/0263276407075956
Latzer, M., & Festic, N. (2019). A guideline for understanding and measuring algorithmic governance in everyday life. Internet Policy Review, 8(2). https://policyreview.info/articles/analysis/guideline-understanding-and-measuring-algorithmic-governance-everyday-life
Lazzarato, M. (2002). From biopower to biopolitics. Pli: The Warwick Journal of Philosophy, 13, 100 – 112.
Li, T. M. (2007). Governmentality. Anthropologica, 49(2), 275 – 281.
Lorusso, S. (2021, December 2). The User Condition: Computer Agency Behaviour. https://theusercondition.computer/
McQuillan, D. (2022). Resisting AI: An anti-fascist approach to artificial intelligence (1st edition). Bristol University Press.
Matzner, T. (2019). The human is dead – Long live the algorithm! Human-algorithmic ensembles and liberal subjectivity. Theory, Culture & Society, 36(2), 123 – 144. https://doi.org/10.1177/0263276418818877
Mejias, U. A., & Couldry, N. (2019). The costs of connection: How data is colonizing human life and appropriating it for capitalism. Stanford University Press.
Milan, S. (2018). Digital traces in context: Political agency, digital traces, and bottom-up data practices. International Journal of Communication, 12(0), 21.
Nagy, P., & Neff, G. (2015). Imagined affordance: Reconstructing a keyword for communication theory. Social Media + Society, 1(2), 1–9.
https://doi.org/10.1177/2056305115603385
Neff, G., Jordan, T., McVeigh-Schultz, J., & Gillespie, T. (2012). Affordances, technical agency, and the politics of technologies of cultural production. Journal of Broadcasting & Electronic Media, 56(2), 299 – 313.
https://doi.org/10.1080/08838151.2012.678520
Neff, G., & Nagy, P. (2016). Talking to bots: Symbiotic agency and the case of Tay. International Journal of Communication, 10, 4915 – 4931.
O’Hara, K., & Hildebrandt, M. (2020). Between the editors. In M. Hildebrandt & K. O’Hara (Eds.), Life and the law in the era of data-driven agency (pp. 16 – 43). Edward Elgar Publishing. https://www.elgaronline.com/view/edcoll/9781788971997/9781788971997.00007.xml
Pohle, J., & Thiel, T. (2020). Digital sovereignty. Internet Policy Review, 9(4). https://policyreview.info/concepts/digital-sovereignty
Reviglio, U., & Agosti, C. (2020). Thinking outside the black-box: The case for “algorithmic sovereignty” in social media. Social Media + Society, 6(2), 2056305120915613. https://doi.org/10.1177/2056305120915613
Roio, D. (2018). Algorithmic Sovereignty [Thesis, University of Plymouth]. Pearl. https://pearl.plymouth.ac.uk/handle/10026.1/11101
Ronzhyn, A., Cardenal, A. S., & Batlle Rubio, A. (2022). Defining affordances in social media research: A literature review. New Media & Society, 14614448221135188. https://doi.org/10.1177/14614448221135187
Rose, N., O’Malley, P., & Valverde, M. (2009). Governmentality (SSRN Scholarly Paper No. 1474131). https://papers.ssrn.com/abstract=1474131
Rouvroy, A. (2011). Technology, virtuality and utopia: Governmentality in an age of autonomic computing. In Law, Human Agency and Autonomic Computing. Routledge.
Rouvroy, A. (2013). The end(s) of critique: Data behaviourism versus due process. In M. Hildebrandt & K. De Vries (Eds.), Privacy, due process and the computational turn. Routledge.
Rouvroy, A. (2020, March 27). Algorithmic Governmentality and the Death of Politics [Green European Journal]. https://www.greeneuropeanjournal.eu/algorithmic-governmentality-and-the-death-of-politics/
Rouvroy, A., & Berns, T. (2010). Le nouveau pouvoir statistique. Ou quand le contrôle s’exerce sur un réel normé, docile et sans événement car constitué de corps « numériques »... Multitudes, 40(1), 88 – 103.
https://doi.org/10.3917/mult.040.0088
Rouvroy, A., & Berns, T. (2013). Algorithmic governmentality and prospects of emancipation (L. Carey-Libbrecht, Trans.). Reseaux, 177(1), 163 – 196.
Rouvroy, A., & Poullet, Y. (2009). The right to informational self-determination and the value of self-development: Reassessing the importance of privacy for democracy. In S. Gutwirth, Y. Poullet, P. De Hert, C. de Terwangne, & S. Nouwt (Eds.), Reinventing Data Protection? (pp. 45 – 76). Springer Netherlands. https://doi.org/10.1007/978-1-4020-9498-9_2
Rouvroy, A., & Stiegler, B. (2016). The digital regime of truth: From the algorithmic governmentality to a new rule of law. La Deleuziana, 3, 6 – 29.
Savolainen, L., & Ruckenstein, M. (2022). Dimensions of autonomy in human–algorithm relations. New Media & Society, 14614448221100802. https://doi.org/10.1177/14614448221100802
schraefel, m. c., Gomer, R., Gerding, E., & Maple, C. (2020). Rethinking transparency for the Internet of Things. In Life and the Law in the Era of Data-Driven Agency (pp. 100 – 116). Edward Elgar Publishing. https://www.elgaronline.com/view/edcoll/9781788971997/9781788971997.00012.xml
Schuilenburg, M., & Peeters, R. (2020). The algorithmic society: Technology, power, and knowledge. Routledge.
Tkacz, N., Henrique da Mata Martins, M., Porto de Albuquerque, J., Horita, F., & Dolif Neto, G. (2021). Data diaries: A situated approach to the study of data. Big Data & Society, 8(1), 2053951721996036.
https://doi.org/10.1177/2053951721996036
van Dijck, J. (2014, July 23). Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology. Surveillance & Society, 12(2), 197 – 208. https://doi.org/10.24908/ss.v12i2.4776
Veale, M. (2019). A better data access request template. Michael Veale.
https://michae.lv/access-template/
Volkoff, O., & Strong, D. M. (2017). Affordance theory and how to use it in IS research. In R. Galliers & M-K. Stein (Eds.), The Routledge companion to management information systems. Routledge.
Weiskopf, R., & Hansen, H. K. (2022). Algorithmic governmentality and the space of ethics: Examples from ‘People Analytics.’ Human Relations, 00187267221075346. https://doi.org/10.1177/00187267221075346
Acknowledgement
The research was done as part of the project DELICIOS “An integrated approach to study the delegation of conflict-of-interest decisions to autonomous agents” (G054919N), funded by the Fonds voor Wetenschappelijk Onderzoek – Vlaanderen (FWO).
Date received: January 2023
Date accepted: June 2023