
Too Far Away from the Job Market – Says Who?
Linguistically Analyzing Rationales for AI-based Decisions Concerning Employment Support
1 Introduction
As artificial intelligence (AI) is increasingly being deployed in various domains, such as healthcare, finance (Dastile et al., 2020), and public welfare (Carney, 2020; Saxena et al., 2020), there is a growing need to understand how stakeholders are affected by AI, as well as how to design and present explanations of AI-based decisions in practical and comprehensible ways (Henin & Le Métayer, 2022; Miller, 2019; Mittelstadt et al., 2019). This paper contributes to these efforts by examining an AI-based decision-support system (DSS) launched by the Swedish Public Employment Service (PES) in 2020 to assist enrolment decisions in an employment support initiative. Specifically, the study focuses on how decisions are explained in formal letters from the agency to jobseekers. Informed by previous research concerning explanations in relation to trust, appealability and procedural fairness, as well as jobseekers’ needs and interests concerning algorithmic decision-making, the study linguistically analyses the extent to which the system enables affected jobseekers to understand the basis of decisions and to appeal or take other actions in response to automated assessments. The study also analyses the degree to which the rationales behind decisions accurately reflect the actual decision-making process. Particular attention is given to linguistic aspects of explainability, primarily motivated by the fact that decisions are explained to jobseekers in natural language (rather than, for instance, diagrams).
The remainder of the paper is structured as follows: Section 2 outlines the theoretical framework, while Section 3 situates the study in relation to previous work. Section 4 introduces the empirical material by providing background to the studied DSS and exemplifying how AI-assisted decisions are explained to jobseekers. The main contributions of the paper are then presented in Section 5, which linguistically analyses various aspects of the system’s explainability, and in Section 6, which discusses how explainability could be improved. Finally, Section 7 draws several conclusions.
2 Theoretical Framework
The role and function of explanations in relation to algorithmic and AI-assisted decision-making has been widely researched, both in the context of public administration and more generally. Explanations enable affected subjects to assess whether a decision (and the decision-making process at large) can be trusted (Grimmelikhuijsen, 2023). For example, Kizilcec (2016) observed that students trust an algorithmic grading system more if the received grade is accompanied by an explanation. Furthermore, explanations enable subjects to contest unpreferred decisions (Henin & Le Métayer, 2022; Mittelstadt et al., 2019). For example, if an individual’s application for sickness benefit is denied, an explanation can help said individual assess whether aspects of the decision-making process could be questioned or appealed. More generally, explanations can foster procedural fairness (Tyler, 2006), i.e., trust based on a perception of a fair decision-making process, as well as accountability (Busuioc, 2021).
In the specific context of PES, Scott et al. (2022) studied jobseekers’ needs and desires in relation to algorithmic tools, highlighting the former’s interests in intelligibility (system outputs should be comprehensible) and empowerment (systems should support jobseekers by providing actionable information). The present study uses these desiderata as evaluation criteria for its empirical analysis, while noting that the desiderata are consistent with several of the general functions of explanations highlighted in previous discourse concerning AI applications in public administration, such as trust and appealability.
Generally speaking, it has often been argued that, in order to obtain important values (trustworthiness, accountability, etc.), explanations should accurately reflect the actual decision-making logic (Phillips et al., 2021; Rudin, 2019). In other words, the mere presence of an explanation does not suffice; its content must also be relevant and accurate. However, issues concerning the linguistic design of AI explanations – i.e., the main focus of the present study – have received less attention. Miller (2019) surveyed research on explanations in the social sciences and argued that they should, ideally, be contrastive (i.e., explain why one outcome, rather than another, was obtained), selective (e.g., focus on the most relevant aspects and not be overly detailed), causal (rather than merely statistical), and interactive. Breitholtz (2020) and Maraev et al. (2021) noted that, in human communication, the act of producing and interpreting explanations falls under a more general process of enthymematic reasoning, i.e., communicating with implicit reference to shared background knowledge. For example, when someone explains a proposed choice of route by saying that it is shortest, the listener makes sense of the statement in light of a mutually shared but unstated principle that short routes are preferable to long ones. In line with this, the authors argue that AI systems become more comprehensible if they can explain their predictions with implicit reference to background knowledge.1 The present study builds on this notion of enthymematic reasoning, both in its analysis of intelligibility and its suggested improvements.
3 Related Work
Previous studies have investigated the use of AI and algorithms in the context of PES from the perspectives of accuracy and discrimination (Desiere et al., 2019; Desiere & Struyven, 2021), norms and values embedded in algorithms (Sztandar-Sztanderska & Zielenska, 2020), austerity politics (Allhutter et al., 2020), caseworkers’ attitudes and strategies (Assadi & Lundin, 2018; Sztandar-Sztanderska & Zieleńska, 2022), jobseekers’ needs and desires (Scott et al., 2022), automation bias (Ruschemeier, 2023), and legal certainty (Carlsson, 2023). While few previous works have analyzed explainability in relation to PES, exceptions include Niklas et al. (2015), who investigated the transparency of a Polish algorithmic profiling system, and Zejnilovic et al. (2021), who studied the effects of explanations on caseworkers’ decisions.
As for the specific case at hand, Berman et al. (2024) assessed the trustworthiness of Swedish PES’ AI-based system in terms of various criteria, including interpretability, accountability, and fairness. This paper extends this work by linguistically analyzing explainability from the perspective of jobseekers’ needs and interests.
4 Case Description
The material analyzed in this paper is based on public sources (cited where relevant) and information received from the agency via email (Nov 2021– Oct 2023).
In 2019, the Swedish government decided that a statistical tool 2 should be developed as an integrated part of the operations of the PES in order to improve consistency and accuracy of labor-market related assessments, and thereby improve the efficiency of resource allocation. 3 Subsequently, the employment initiative Prepare and Match (PAM) was launched in 2020 and nationally rolled out in 2021 (Hansson & Luigetti, 2022). 4 The initiative enables enrolled jobseekers to receive support, such as in the form of training or guidance, from a chosen provider. Decisions about access to the initiative are largely based on outputs from an AI-based DSS. (For technical details concerning the DSS, see Section 5.3.)
Potential enrolment in PAM is discussed in a meeting between the jobseeker and a caseworker. For caseworkers, an automated recommendation is shown in the case management system and is accompanied by a ranked list of 10 factors deemed relevant to the decision. Once the enrolment decision has been made, it is also sent as a letter to the jobseeker. (Written statements for negative decisions are sent to jobseekers only on request.) The letter contains both the decision (whether the jobseeker is enrolled in PAM) and a rationale for it. These rationales constitute the main objects of analysis in the current study, since their purpose is to convey the basis for a particular decision. Below is an example of a rationale for a positive decision, i.e., that the jobseeker enrolled in PAM (own translation) 5:
By comparing your information with statistics, we have tried to assess how near you are to the job market. Our assessment is that you will get the best help from a supervisor at one of the providers within the Prepare and Match initiative. In your case, it was primarily the following factors that contributed to the assessment: your unemployment duration, your unemployment history, your city of residence, and working time.
Negative decisions state either that the jobseeker is “near to” or “far away from” the job market, and that this “means that the jobseeker is not offered [a placement within] Prepare and Match.”
Further to written statements concerning specific decisions, general information on statistical profiling is also offered to jobseekers on the agency’s web site (Arbetsförmedlingen, n.d.). Under the headline, “How we assess how quickly you can get a job and what support you need”, the agency writes:
When you register with the Swedish Public Employment Service, we assess how quickly you can get a job and what support you need. We use a statistical assessment support tool. It is an automatic method for processing personal data and is based on the information you have provided to us. The purpose is to help you find a job as soon as possible.
The web page also lists 26 types of information used in the automated processing (country of birth, county, age, etc.).
5 Explainability Analysis
Previous studies of the DSS have shown that agency officials find it difficult to understand the basis for specific decisions, sometimes referring to the system as a black box (Bennmarker et al., 2021; Carlsson, 2023). The below analysis may illuminate why this is the case, although it takes the perspective of affected jobseekers rather than caseworkers. Following Scott et al. (2022), the explainability analysis focuses on jobseekers’ interests in intelligibility (system outputs should be comprehensible) and empowerment (systems should support the jobseeker by providing actionable information). Additionally, explanation accuracy is assessed, i.e., the extent to which explanations correctly reflect the processes and circumstances that they are intended to elucidate (Phillips et al., 2021). 6
In what follows, rationales for decisions are first linguistically analyzed to unpack their explanantia (sg. explanans), i.e., the content that serves to explain something, as well as their explananda (sg. explanandum) (Hempel & Oppenheim, 1948), which here refers to the aspects of the decision-making process that the rationales serve to explain. The identification of explanantia and explananda, as well as potential ambiguities in these regards, paves the way for the subsequent analysis of intelligibility. The degree of accuracy of the identified explananda is then assessed by analyzing the actual decision-making process and comparing it with how it is conveyed to jobseekers. Finally, the extent to which rationales for decisions empower jobseekers is discussed.
5.1 Linguistic Analysis
As a starting point for the linguistic analysis, we first note that, in natural language, whether something is an explanation or is being explained is occasionally signaled with specific words and syntactic structures, such as “X because Y” or “X, therefore Y.” However, in many cases, the presence of and relation between explanantia and explananda cannot always be immediately determined from surface form alone (Sbisa, 2011). For example, in the utterance (1) “It’s cold in here, so let’s close the window,” the explanans (the speaker’s perception of cold) and the explanandum (the suggestion to close the window) are explicitly signaled via the word “so” and how it connects the two clauses. In contrast, consider the utterance (2) “Let’s close the window, it’s cold in here.” Clearly, utterances (1) and (2) have identical meanings, at least in terms of explanatory content; the only difference is that (2) signals the relation between explanans and explanandum less explicitly. 7
Turning to the case at hand, one can observe an explicit link between the decision (explanandum), communicated under the headline “Decision” in the formal letter, and its explanans, conveyed under the headline “Rationale for decision.” However, when examining the rationale more closely (see Section 4), its explanatory structure and content appears to be somewhat ambiguous (see Figure 1), partly due to the implicit signaling of how its different parts are semantically connected. 8 The first sentence explains that “statistics” is used to “assess how near” the jobseeker is to the job market, which seems relatively straightforward (although the notion of distance can raise questions; see Section 5.2). Then, the second sentence, “Our assessment is that you will get the best help from a supervisor at one of the providers within the Prepare and Match initiative,” allows for at least two interpretations: Either the assessment that PAM is the best option is made with statistics, or on the basis of the distance to job market (which in turn is assessed using statistics). Furthermore, since the nature of PAM (the existence of a supervisor and several providers) is mentioned, it is potentially implied that this nature is somehow considered when assessing PAM’s suitability, as in “Prepare and Match is suitable for you partly because you will get a supervisor and the ability to choose a provider.” If the reader were to make this interpretation, it would still, however, remain unclear whether this nature is considered as part of the statistical assessment, or by some other means. The relation between distance to job market and PAM’s suitability also seems unclear, partly due to there being no indication of how near to the job market the jobseeker is assessed to be.
Figure 1: Visualization of explanatory structure of rationales for decisions, as revealed by the linguistic analysis
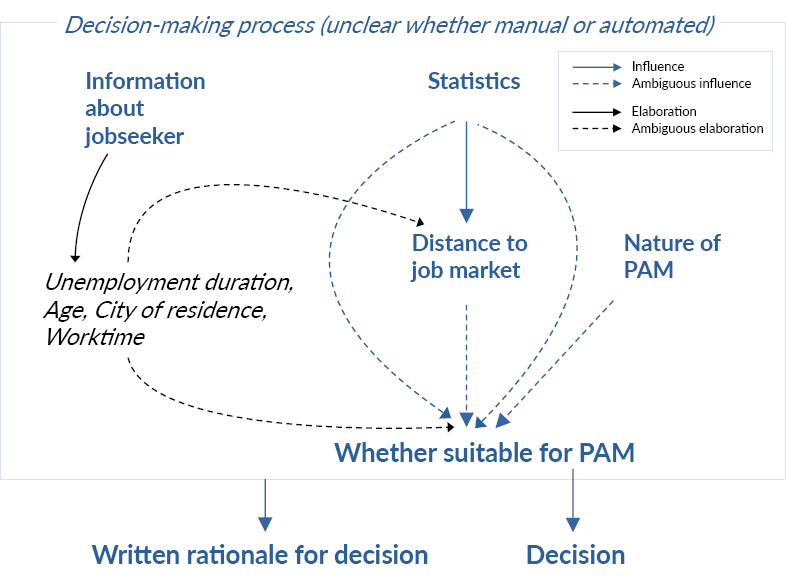
Note: Arrows indicate influence on decisions. For example, the arrow from “Whether suitable for PAM” to “Decision” denotes that, in rationales for decisions, it is indicated that the assessment concerning a jobseeker’s suitability for PAM influences the decision.
Additional ambiguities are raised by the last sentence, which lists four factors (employment duration, age, city of residence, and worktime) that “primarily […] contributed to the assessment.” First, the noun phrase “the assessment” can refer back either to the assessment of distance to job market (sentence 1) or to the assessment of PAM’s suitability for the jobseeker (sentence 2), raising uncertainty regarding exactly to what the factors contribute. Second, it seems unclear what it means for a factor to contribute to an assessment (regardless of what the assessment concerns). Arguably, a statement that some set of factors contributes to some judgement is a fairly vague and imprecise elaboration of the relation between them. In contrast, one can imagine a statement such as “since you have been unemployed for more than 12 months […], our assessment is that […]”, where the relation between factors and judgement is presented with more detail. On a pragmatic level, one possible interpretation of the decision letter’s lack of precision is that the agency knows exactly how factors underpin decisions, but for some reason cannot or does not want to reveal this information. Reasons for intentional omission may include the desire to not be overly detailed or verbose (in line with Grice’s (1975) maxim of quantity), or an unwillingness to disclose secret or potentially demotivating information. Another interpretation is that the agency lacks knowledge about exactly how factors underpin decisions. The existence of several potential reasons for the agency’s imprecision constitutes an ambiguity in its own right.
Finally, on a more general level one can observe that the agency mentions two different sources of expertise and judgement: “we” and ”statistics.” Given that the letter includes the agency’s name and logo and is signed by a caseworker, “we” presumably refers to both the caseworker specifically and the agency at large. There is also an implied hierarchy between the two knowledge sources in that “we” make assessments using “statistics.” However, the decision letter does not mention whether some aspects of the decision-making process are manual or automated. This ambiguity concerns not only decisions, but also how decision letters are authored. Indeed, the reader may infer the involvement of some form of automation during the assessment, but that the caseworker has the final say and formulates the decision letter. As Section 5.3 shows, only the first half of this interpretation is accurate.
5.2 Intelligibility
As shown in the linguistic analysis in Section 5.1, rationales for decisions are ambiguous in various aspects, including the role of statistics in the decision-making process, the extent to which the nature of the employment initiative is taken into account, and the influence of the jobseekers’ information. Presumably, the large amount of ambiguities decreases the intelligibility of the rationales. Moreover, it is unclear whether the phrase “how near you are to the job market” should be understood literally (i.e., geographically) or metaphorically (e.g., in terms of how long it is expected to take to find employment, or how much effort it is expected to require).
As for the list of factors, as discussed in Section 5.1, there is a striking lack of detail in the communication of how the factors contribute. Nevertheless, this does not necessarily mean that a list of factors is incomprehensible as an explanation for some assessment. Human communication abounds with implicit premises – pieces of information that senders do not explicitly refer to in their statements and that addressees need to be able to identify or (re)construct during the act of comprehension (Breitholtz, 2020). For example, we can consider a situation where a doctor tells an 80-year-old patient that “Due to your age, I recommend that you get a flu vaccination.” In such a scenario, the patient may readily accommodate the premises that the elderly have a heightened risk of developing serious complications from flu, and that an age of 80 is considered high in this context. Similarly, we can consider a jobseeker who has been unemployed for one month and receives a decision stating that their unemployment duration contributed to the assessment that they are too near to the job market. In such a situation, it seems reasonable to accommodate the premise that a short duration of unemployment is associated with being near to the job market, and that one month of unemployment is considered short in this context. To this end, it is perhaps not evident that the agency’s lack of detail concerning influence of factors impedes comprehension.
However, there may be situations where the specific ways in which highlighted factors impact an assessment are not evident, even in light of commonsense background knowledge. After all, one should not assume that an AI would make its assessments in similar ways to a human – especially if one of its purposes is to make better assessments than humans. For example, let us consider a jobseeker who has been unemployed for one year, is 45 years old, and is deemed suitable for PAM (i.e., moderately close to the job market). Are both factors associated with a moderate distance to the job market? Or is one of the circumstances associated with a short distance and the other with a long distance in a way where the two influences negate each other? In such a situation, there is a risk that the jobseeker falsely perceives themselves to understand the explanation, by way of accommodating an inaccurate premise regarding how the system actually makes its assessments. Another (perhaps more desirable) risk is that the jobseeker simply does not understand the explanation. Such a mechanism might explain why caseworkers, who receive similar information about factor importance, have reported that “[o]ne cannot really figure out why one got a particular decision […] sometimes one cannot really understand what tilts the scale if one gets a no, for example” (Bennmarker et al., 2021, own translation).
5.3 Explanation Accuracy
To assess the degree of correspondence between explanantia and explananda, one must examine the actual decision-making process that the rationales for decisions are intended to elucidate. In the analysis of intelligibility in Section 5.2, we primarily took the perspective of a jobseeker lacking detailed knowledge about how the Swedish PES uses AI. Here, we temporarily switch perspective and observe the DSS from the inside, informed by reports and information received from the agency.
Technically, decisions about access to the employment initiative are partly based on a statistical estimate of the jobseeker’s probability of finding a job within six months. The statistical analysis encompasses 26 variables pertaining to personal information, including age, gender, education, and previous unemployment activities. It also involves data about the jobseeker’s postal area, including levels of unemployment, income, education, and citizenship (Bennmarker et al., 2021).
The statistical model is a neural network trained on historical data consisting of 1.1 million profiles (information about a jobseeker at a particular moment in time) collected over a 10-year period. The model estimates probabilities for 14 different future employment statuses; the DSS uses the sum of two of two outputs, corresponding to the probability of being employed within six months, either permanently or on fixed-term / part-time basis (Bennmarker et al., 2021). The statistically estimated probability is combined with the jobseeker’s current unemployment duration using threshold functions (see Figure 2) into three possible outcomes (Arbetsförmedlingen, 2020):
1) Too near to the job market;
2) Suitable for PAM;
3) Too far away from the job market.
Figure 2: Relationship between estimated probability of finding a job, number of days of current unemployment, and recommended outcome (as of December 7, 2020)
 Source: Bennmarker et al. (2021)
Source: Bennmarker et al. (2021)
Individuals that are near to the job market (Outcome 1) are assessed as having a limited need for support, while those that are very far from the job market (Outcome 2) are assessed as needing more substantial support. Hence, PAM is offered when the need for support is, in some sense, moderate. Importantly, this assessment (or assumption) concerning the relation between job chance and unemployment duration on the one hand, and need for support on the other, is not conducted by the AI. It should also be noted that the thresholds between different outcomes are subject to political or administrative decisions related to such factors as available resources, and that they are occasionally adjusted (Bennmarker et al., 2021; Böhlmark et al., 2021).
Decision rationales are automatically generated using a template with slots for the outcome (whether the jobseeker is deemed suitable or too near / far to the job market) as well as for a list of contributing factors. Caseworkers are instructed not to modify the automated generated rationale. 9 In the rationale, unemployment duration is always presented as the most important factor. The rest of the factors are ranked using Local Interpretable Model-agnostic Explanations (LIME; see Ribeiro et al., 2016).
Caseworkers are instructed to primarily adhere to the automated recommendation. Overruling a negative decision is difficult since it requires contacting a special working group within the agency. Interviews with caseworkers have indicated that some are reluctant to use this option since the working group rarely admits exceptions from automated recommendations (Bennmarker et al., 2021). 10
Against the technical and organizational backdrop provided above (visualized in Figure 3), we can now assess how well rationales reflect the actual decision-making process. An immediate observation is that some aspects of the decision-making process are not explained to jobseekers. Perhaps most pertinently, while decisions are partly governed by thresholds that are continuously adjusted by the agency, the role and function of these are mentioned neither in rationales for specific decisions nor on the agency’s website. Arguably, concealing some of the circumstances that underpin decisions impedes jobseekers’ ability to understand the basis for the decisions. For example, if the agency raises the threshold for positive decisions, some jobseekers may receive a negative decision as a direct consequence of the changed threshold without being informed about this circumstance.
Figure 3: Visualization of decision-making process as revealed by organizational and technical analysis
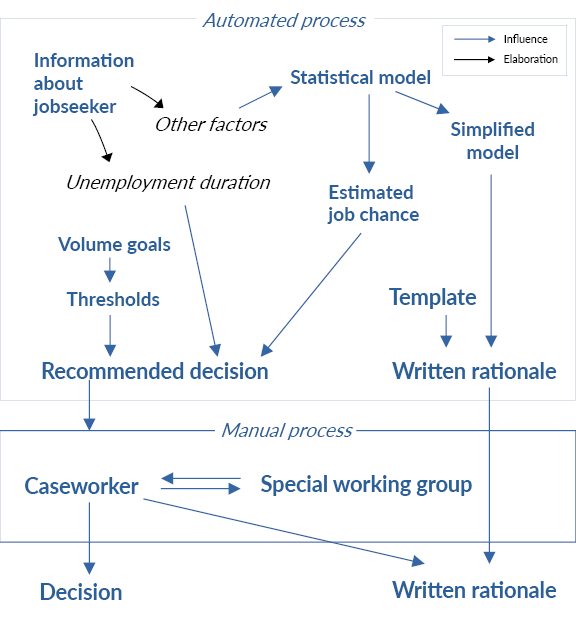
On a more general level, the technical and organizational analysis reveals that the intended purpose of the thresholds is to target those individuals that are most likely to find a job through PAM, while simultaneously adhering to volume goals linked to budgetary restrictions. In other words, the system as a whole is designed to optimize two goals: most suitable intervention for each jobseeker in relation to their need, and overall compliance with volume goals. Hence, the reality behind such words as “too near” or “too far away from the job market” involves not only the individual jobseeker’s situation and needs, but also the situation and needs of the agency. In this respect, the communication to jobseekers seems potentially misleading.
On a related note, it is worth emphasizing that the statistical model merely estimates a jobseeker’s need of support (in terms of probabilities of future employment statuses), without considering the potential interventions made on the basis of such assessments. In reality, the distribution of labor (and responsibility) between humans and AI is relatively straightforward in this regard. However, decision rationales suggest (or, at least, do not preclude) that PAM’s suitability for a jobseeker is assessed with statistics and by taking the nature of the intervention into account. This discrepancy constitutes another instance of potentially misleading communication.
As for the list of important factors, the analysis in Section 5.2 highlighted several difficulties in grasping what such a list actually means. However, a lack of intelligibility does not necessarily imply a lack of accuracy. For example, if a jobseeker’s age is indeed an important factor underpinning a specific decision, then it would be pertinent to mention age, even if the exact nature of the influence is not clearly presented. Conversely, mentioning age as important can be inaccurate if its influence is in fact neglectable for the decision at hand.
When assessing the accuracy of factor importance attributions, one must first observe that one part of the list (the top item) pertains to the decision-making process at large, while the rest relates to the specific decision. From the perspective of intelligibility, this seems somewhat obscure, since no difference between positions in the list is signaled linguistically. Furthermore, in terms of accuracy, the leading phrase “In your case, it was the following factors […]” is misleading, since the top item is not case-specific in reality. In addition, a closer look at the decision-making logic reveals that the alleged importance of unemployment duration seems dubious. As illustrated by Figure 2, the actual effect of unemployment duration on decisions diminishes as duration increases. For jobseekers who have been unemployed for a long time, the job chance (estimated on the basis of other factors) arguably has a greater impact on decisions than unemployment duration. Consequently, always mentioning unemployment duration as the most important factor seems potentially inaccurate.
It is also doubtful whether the rest of the factors (Position 2 – 4) accurately reflect the real decision-making logic. Ideally, these factors should in some way refer to the statistical assessment of job chance. However, as noted above, the estimated job chance is only one component of the decision-making logic. This creates a discrepancy between what is implied (namely that Factors 2 – 4 are important for the overall assessment) and the underlying technical reality (namely that Factors 2 – 4 are important for the assessment of job chance). This discrepancy is particularly pertinent in cases where unemployment duration and estimated job chance affect decisions in different directions. For example, we can consider a 50-year-old jobseeker with an estimated job chance of 40 % who has been unemployed for 2 weeks, yielding Outcome 1 (too near to the job market). We also assume that the jobseeker’s age has significantly decreased the estimated job chance. In the decision letter, age is included among the important factors, implying that it contributed to the assessment that the jobseeker is near to the job market, when in fact the opposite is true. Arguably, it would have been more accurate to state that, although the jobseeker’s age is deemed to increase the distance to the job market, the short duration of unemployment suggests the distance to be short. (Section 6 provides more elaborate suggestions for how both intelligibility and accuracy can be improved.)
So far, the discussion concerning factor importance attribution has focused on linguistic design choices with respect to how importance attributions obtained with LIME are presented to jobseekers. Previous research has also highlighted more general concerns regarding LIME’s accuracy (and similar so-called post-hoc explanation methods). Fundamentally, LIME approximates the model to be explained by simplifying its decision-making logic for specific decisions. Technically, this is achieved by creating a much simpler surrogate model that roughly mirrors how the actual model behaves for cases similar to the input at hand. The respective contributions of different factors are then approximated by inspecting what the surrogate model has learned. For example, if the neural network (the model to be explained) predicts a 20 % probability of finding a job within 6 months, LIME may explain that age contributes with +0.4 %, education level with –0.3 %, etc. This is how the Swedish PES ranks factors by their importance. However, LIME suffers from accuracy issues, in that its explanations pertain to a simplified model that does not always reflect the actual logic of the model to be explained. This circumstance manifests itself in various ways. For example, LIME can be inconsistent in producing different explanations for the same prediction (Amparore et al., 2021). Furthermore, LIME and similar post-hoc explanation methods often contradict each other in their ranking of the most important factors (Krishna et al., 2022). Consequently, even in situations where unemployment duration and estimated job chance point in the same direction, the ranking of factors is potentially inaccurate, since the underlying explanation method is fundamentally unreliable.
5.4 Empowerment
Several of the concerns regarding intelligibility and accuracy of explanations affect empowerment, such as regarding conditions for contesting unfavored decisions. The ability to appeal decisions is an important aspect of public welfare and administration (Morgan, 1961). Specifically, the Swedish Administrative Procedure Act (2017, p. 900) mandates that a “decision may be appealed if the decision can be assumed to affect some person’s situation in a not insignificant way.” Appealability requires (or is at least facilitated by) intelligible explanations: In lack thereof, it is difficult to assess whether the decision has been made on a solid basis, or to identify potential flaws in the reasoning (Colaner, 2022). In these regards, the extent to which the studied explanations support appealability is impeded by apparent weaknesses in intelligibility.
Appealability hinges not only on comprehensible rationales, but also on particular kinds of explanatory content. Ideally, explanations should present the salient facts pertaining to the case at hand and information concerning how these have been connected, interpreted, and attributed weight in the decision-making process (Olsen et al., 2020). In the context of automated decision-making, the European Parliamentary Research Service recommends that “data subjects who did not obtain the decision they hoped for should be provided with the specific information that most matters to them, namely, with the information on what values for their features determined in their case an unfavorable outcome” (Directorate-General for Parliamentary Research Services (European Parliament) et al. (2020), emphasis added). To illustrate how these properties of explanations can concretely support appealability, let us consider how The Swedish Social Insurance Agency explains a decision to decrease an individual’s sickness benefit:
To be entitled to half disability compensation, the work capability needs to be reduced by at least one half. You have worked 24 hours per week for your employer since January X. Since you managed to work more than half-time for over three months, the Social Insurance Agency deems that your work ability has improved significantly. Therefore, you cannot receive more than one quarter disability compensation. (Försäkringskassan, 2005, own translation)
In response to this rationale, a subject may object to the salient facts presented (e.g., by arguing that the agency’s records of the subject’s work time are incorrect), or how the facts have been interpreted and attributed weight (e.g., by arguing that the subject’s work capability has not been improved, as evidenced by information that the agency has not considered). In contrast, and as discussed in Section 5.2, explanations for the Swedish PES’ decisions concerning enrolment in PAM do not convey any case-specific facts at all. The four factors that have been attributed weight are merely named (unemployment duration, age, etc.), without elaborating their values (e.g., that the jobseeker has been unemployed for eight months), or how these are combined and interpreted into an outcome. Arguably, this prevents the jobseeker from understanding, and thereby contesting, the basis for a decision.
Another property of explanations that can support appealability is counterfactuality (or contrastiveness) (Wachter et al., 2017), i.e., conveying the conditions under which another (potentially more favorable) decision would be warranted. The example from the Swedish Social Insurance Agency implies that if the individual had worked half time or less, the agency would not have deemed the subject’s work capability to have significantly improved, and therefore not reduced sickness benefit. This kind of counterfactual reasoning is difficult to perform if important factors are merely named. For example, the sheer highlighting of “city of residence” does not explain whether living in another city would affect the decision. Counterfactual reasoning is also inhibited by a lack of information concerning the boundaries between outcomes. For example, if a jobseeker is deemed too far from the job market, no information is presented concerning how much nearer they would need to be in order to be considered suitable for PAM.
Some authors have recommended providing explicit counterfactual explanations for AI-based decisions (see e.g. Wachter et al., 2017) and demonstrated that such explanations can be provided even for such opaque predictive models as neural networks. For example, if the jobseeker is deemed too far from the job market, the decision letter could explicitly state the conditions under which the jobseeker would be deemed suitable for PAM, such as a particular level of education. However, since counterfactual explanations are selected on the basis of notions of feasibility that may differ between subjects (Berman et al., 2022; Rudin, 2019) – for example, further education may be more feasible for some jobseekers than others – they may be inappropriate in formal decision statements. (This problem concerns potential changes in factors, not distance to decision boundaries.) However, as discussed in Section 6.3, the subjective nature of feasibility can be handled via some form of interaction between system and jobseeker.
It is worth stressing that the above discussion on appealability concerns not only legal contestation, but also the involvement of jobseekers in the decision-making process before a decision is made. In principle, jobseekers could contest the system’s recommended decision during the meeting with the caseworker, and object against the rationale presented by the system to the caseworker. However, this ability hinges on the same requirements that underpin appealability after a decision is made (i.e., the highlighting of facts, elaboration of reasoning, and contrastiveness).
Another aspect of jobseeker empowerment that is relevant in the context of AI and employment services is the former’s potential role as a coach (Scott et al., 2022). To the extent that the AI has learned something relevant about employability, informative explanations could potentially be used as advise for how to close the distance to the job market. For example, if a jobseeker were to be informed that their lack of occupation-specific education is deemed as having a significant negative influence on their job chances, this information could potentially empower the jobseeker by indicating how such chances could instead be increased. However, in their current form, the agency’s explanations seem too vague and imprecise to yield any such benefit.
Improving Explainability
The analysis in the previous section highlighted several limitations in the explainability of the studied DSS. To address these concerns, it would be fruitful to first analyze the root causes behind the identified weaknesses. One such cause is the discrepancies between the actual the decision-making process and how it is conveyed to jobseekers. For example, rationales for decisions as currently formulated suggest that the nature of PAM is considered when assessing the intervention’s suitability. In contrast, it might be more accurate to state that suitability is assessed in part via thresholds that serve to manage the volume of overall enrolment. These weaknesses in explainability are a consequence of linguistic / rhetorical choices that could potentially be made in different ways.
A second cause of the observed weaknesses is that the DSS does not capitalize upon the interpretability of the higher-order decision-making logic through which the output from the statistical model is weighed against the jobseeker’s unemployment duration. Unlike the internal workings of the statistical model, the higher-order logic is fairly trivial and has properties that are usually considered attractive from an interpretability perspective (Rudin et al., 2022). First, the number of variables (two) is very small. Second, the influence of these two variables in the output is monotonic in such a way that seems consistent with human intuitions: A longer duration of unemployment and a lower estimated job chance always increase “distance to job market,” and vice versa. This makes it possible to accurately and intelligibly pinpoint exactly how the estimated job chance and the unemployment duration contribute to the assessment of “distance to job market.”
However, it is not evident that “estimated job chance” is a meaningful notion when it does not fully account for current unemployment duration (which is one of the most predictive factors). Arguably, a model that estimates job chances without considering unemployment duration seems analogous to one that predicts risk of developing dementia without considering the patient’s age. In other words, leveraging the interpretability of the higher-order decision-making logic may not be fruitful if one of its components is inherently enigmatic. To this end, it may be conceptually more intuitive to instead include unemployment duration in the statistical model. This way, it becomes unproblematic to interpret the output from the statistical model as an estimated job chance. Furthermore, through such a change, only one of the terms “job chance,” “distance to job market,” or “need for support” would be required.
Third, some of the identified limitations boil down to a lack of direct communication between system and jobseeker. Currently, the system’s assessments are only explained in the form of a written rationale shared with the jobseeker after a decision has been made. To the extent that a jobseeker would appreciate answers to such questions as “What if I move to Stockholm?,” there is no way to ask the system such questions. Hence, jobseekers could potentially benefit from an ability to interact more directly with the system. (Similar recommendations have previously been discussed in the context of AI explainability more generally; see, for example, Arya et al. (2019); Cheng et al. (2019); Lakkaraju et al. (2022); Simkute et al. (2021); Weld and Bansal (2019).)
Finally, several observed weaknesses in explainability are caused by the opacity of the statistical model. As described in Section 5.3, decisions are partly made on the basis of a statistical prediction of the jobseeker’s chances of finding future employment. This prediction is made by a neural network whose logic, due to non-linear processing and complex interactions between variables, is difficult for humans to grasp. Presumably, even AI experts with full access to the model cannot understand how it reaches particular judgements. Accordingly, assessments made with the help of the AI can only be explained in approximate and imprecise terms. Consequently, improvements can potentially be made by switching to a more interpretable statistical model.
The following sections discuss potential improvements in explainability, organized according to the root causes of the above-listed concerns.
5.5 Linguistic Choices
In order to more accurately and intelligibly describe how decisions are actually made, rationales could be formulated as follows (in this case, focusing on a positive decision):
To assess whether Prepare and Match (PAM) is suitable for you, we use a statistical assessment support tool which estimates your need for support on the basis of a large number of factors. Based on your estimated need for support and the agency’s current enrolment criteria, jobseekers are placed into one of three categories: too near to the job market for PAM, suitable for PAM, or too far away from the job market for PAM. You have been placed in the category “suitable for PAM.” I agree with this assessment.
In contrast to current decision rationales, the above suggestion more clearly and faithfully accounts for the actual function and over-arching logic of the statistical tool and the existence of agency-controlled thresholds (here referred to as “enrolment criteria”). 11 It is also intended to clearly distinguish the automated and manual aspects of the decision-making process. Moreover, it should be noted that the suggestion assumes a template that should only be used when the caseworker agrees with the automated assessment.
Despite any potential improvements in accuracy and intelligibility, the suggested phrasing may raise certain questions, such as “What is my estimated need for support?” or “What are the enrolment criteria?” To address these, it would, in principle, be possible to communicate the job chance estimated by the statistical model and how job chance and unemployment duration are weighed together. However, as discussed above, since the notion of “job chance” seems nebulous when isolated from unemployment duration, such information could easily be misinterpreted. As such, the above suggestion uses only the term “need for support,” without trying to explain its components.
Due to the weaknesses in accuracy associated with the method that estimates factor importance, it also seems problematic to include factor importance attributions in decision rationales. For this reason, the above suggestion excludes factor importance entirely.
5.6 Conceptual Simplification of Decision-making Logic
Eliminating the special treatment of unemployment duration and including it among the factors that are handled by the statistical model could potentially simplify the decision-making logic on a conceptual level and reduce terminological confusion. It also opens for an increased level of transparency, without necessarily reducing intelligibility or risks for misunderstandings. A single model for estimating job chance / need for support enables a phrasing such as:
[…] On a range from 0 to 10, your need for support is estimated to be 4 (where a higher score indicates a more substantial need for support). With the agency’s current enrolment criteria, Prepare and Match is recommended in the range 3 – 7. […]
Here, the previous notion of “suitable for PAM” is replaced with a more precise numerical measure.12 One of the benefits of such transparency is that it more clearly conveys the boundaries between outcomes, which is beneficial from the perspective of empowerment (see section 5.4).
5.7 Interactivity
If a jobseeker is denied access to the employment initiative, the possibility to ask such questions as “What if I move to Stockholm?” or “What if I get a university degree?” can help jobseekers to not only understand how the AI makes its judgements, but also to use this understanding to contest a decision. To the extent that the AI has learned something relevant about employability, the exploration of hypothetical circumstances also enables the AI to be used as a coach for providing advice on how to reduce the distance to the job market.
Supporting hypothetical (what-if) questions is technically trivial; users need only be equipped with a graphical interface which would allow them to explore how modifying the input affects the output. Interactivity could also, in principle, enable more open-ended counterfactual questions, such as “What would motivate a positive decision in my case?,” where the feasibility of changes in circumstances can be addressed in a dialogue between system and jobseeker (Berman et al., 2022).
5.8 Choice of Statistical Model
All of the potential improvements discussed in the previous three subsections can be implemented without replacing the type of statistical model. However, the suggested changes leave one important gap in explainability, namely how the statistical model reaches its specific assessments. Arguably, no changes in linguistic design or mode of communication can overcome this so-called “black-box” issue. Instead, this kind of gap can only be bridged by replacing the neural network with a more interpretable model (Rudin, 2019).
Two international comparisons can illustrate what such a solution may look like. The Danish PES has used a decision tree with only five variables and very few interactions between them. For example, if a jobseeker is unconfident about finding a job, the model predicts an 83 % risk of future unemployment, regardless of other factors; however, if the jobseeker is more optimistic, the model uses three additional factors (age, previous employment rate, and migration status) to categorize risk of unemployment into three different probabilities (Styrelsen for Arbejdsmarked og Rekruttering, 2020). The simplicity of the model eliminates the need for an approximate explanation method, such as LIME; rather, the model more or less “explains itself.” For instance, assessments made by the Danish model can be explained through such phrases as “Your risk of future employment is estimated to be 64 %. This assessment is based on your own confidence concerning your job prospects (less than 6 months for finding a job), your migration status (immigrant from non-Western country) and your age (above 56).” Due to the model’s small size, it can be conveyed to jobseekers in its entirety, such as in the form of a flowchart. Accessing the whole model also enables counterfactual reasoning, since it is easy to see how an alternative path leads to a different outcome.
The Polish PES has used an algorithm with 24 questions scored from 0 (highest employability) to 8. Depending on the total score, the jobseeker is categorized into one of three profiles (Sztandar-Sztanderska & Zielenska, 2020). Outputs from this kind of algorithm can be explained rather simply, such as by communicating how the most influential answers contribute to the overall assessment. As with the Danish model, counterfactual reasoning (e.g., regarding how to become more employable according to the algorithm) is intuitively facilitated since such information can be readily inferred from the scoring of individual questions. However, it must be noted that these benefits require the scoring criteria to be disclosed, which is not the case with the Polish system (Niklas et al., 2015).
Is a simple and interpretable model, such as a small decision tree or a scoring algorithm, as accurate as a more opaque neural network? Comparing accuracy across countries is difficult due to variations in the data. However, the Swedish PES has experimented with two interpretable models whose accuracy can be compared to the deployed model using the same data. The simplest model (a linear regressor), has an accuracy of 66 %, comparable with 68 % for the deployed model (Ornstein & Thunström, 2021); a slightly more sophisticated model (small decision tree + 6 linear regressors) has an accuracy of 74 % (Helgesson & Ornstein, 2021), that is, better than the deployed model. 13 This suggests that a simpler model can fulfil the stated goals – consistency and accuracy – equally well, or even better, than an opaque model, without the negative consequences for explainability that an opaque model would yield. Switching to a linear regression model would enable the following explanations 14:
[…] The main circumstances that are deemed to decrease your need for support are the beneficial labor-market conditions where you live (-3 points). The main circumstances that are deemed to increase your need for support are your relatively long duration of unemployment (+5 points) and the fact that you seek a part-time occupation (+2 points).
Importantly, such an explanation can be generated on the basis of the actual statistical model and is therefore accurate by design, unlike the ranking of factors currently used by the agency, which is based on potentially inaccurate approximations. From the perspective of empowerment, it also enables the jobseeker to assess the solidity of the reasoning, as well as to potentially dispute the facts on which the assessment has been made and the ways in which these facts underpin the decision.
It is also worth noting that the suggested choice of phrasing is enthymematic in that it rests on implicit premises. For example, the elaboration of the first factor (labor-market conditions) hinges on the premise that, if the labor-market conditions where one lives are beneficial, one would need less support than if the labor-market conditions are disadvantageous. However, it is not evident that readers are always able to identify “missing” premises. This is particularly important in cases where the correlations learned by the statistical model do not align with human intuition. Ideally, as proposed in Section 6.3, jobseekers are given the opportunity to ask the system such questions as “What is the connection between duration of unemployment and need for support?” or “Why is my duration of unemployed considered long?,” thereby enabling the implicit premises to be exposed and potentially challenged. How to technically support such interactions remains an open question at this point, although Maraev et al. (2021) and Berman et al. (2022) have advanced related proposals.
6 Conclusions
This case study of an AI-based decision-support system deployed by the Swedish PES has shown that the rationales behind decisions lack important information and are designed in a way that makes them difficult to interpret and potentially misleading. These weaknesses in explainability may affect jobseekers by influencing the caseworkers’ decision-making. Indeed, if caseworkers were to have access to more intelligible and accurate explanations, their trust in the AI (in either direction, from case to case), as well as the final decisions, could be affected. First and foremost, however, the study has highlighted how the weaknesses impede jobseekers’ ability to understand and contest decisions, and obtain advice on how to increase their employment chances. Arguably, these weaknesses jeopardize fundamental norms and values, such as transparency, legitimacy, and accountability.
One of the root causes behind the identified weaknesses is the so-called “black-box” problem: The DSS is based on a neural network whose inner workings are difficult for humans to comprehend and explain. In the studied case, the problem manifests itself in the fact that mentions of important factors behind specific decisions are both vague and unreliable.
While the black-box problem has received plenty of scholarly attention (see, for example, Rudin, 2019), less focus has been given to the linguistic construal of explanations. Perhaps surprisingly, the current study shows that several of the observed explainability concerns are unrelated to the opacity of the statistical model, and instead underpinned by linguistic decisions concerning how concepts and processes are elucidated in natural language. For example, some aspects of the decision-making process are not communicated at all to affected jobseekers, while others are formulated in ambiguous ways that can easily be misinterpreted.
In response to the identified limitations, the paper has discussed four routes of possible improvements in explainability: linguistically conveying the actual decision-making process more clearly and accurately, conceptually simplifying the decision-making logic, supporting more interactive modes of communication between system and jobseeker, and switching to a more interpretable statistical model. The study also shows how enthymematic reasoning, i.e., implicit references to background knowledge, can explain why current rationales for decisions are sometimes difficult to understand, and how it be used as a theoretical basis for improving intelligibility.
It should be noted that the jobseeker perspective adopted in the present study is largely based on insights from previous research involving jobseekers in somewhat different contexts (Scott et al., 2022). Future research could benefit from empirically validating the linguistic analysis by studying the extent to which affected jobseekers find provided explanations intelligible and useful, e.g., through questionnaires and interviews. Such studies could potentially also involve alternative – for example, more interactive – forms of explanations.
More broadly, the study demonstrates that linguistic design is a relatively unexplored aspect of explainability that deserves more attention in future work concerning AI in relation to fundamental normative dimensions, such as trust, appealability, and accountability, both in the context of employment services and public decision-making more generally.
References
Allhutter, D., Cech, F., Fischer, F., Grill, G., & Mager, A. (2020). Algorithmic profiling of job seekers in Austria: How austerity politics are made effective. Frontiers in Big Data, 3. https://doi.org/10.3389/fdata.2020.00005
Amparore, E., Perotti, A., & Bajardi, P. (2021). To trust or not to trust an explanation: Using LEAF to evaluate local linear XAI methods. PeerJ Computer Science, 7, e479. https://doi.org/10.7717/peerj-cs.479
Arbetsförmedlingen. (n.d.). How we assess how quickly you can get a job and what support you need. Retrieved August 8, 2022, from https://arbetsformedlingen.se/other-languages/english-engelska/about-the-website/legal-information/assessment-and-profiling
Arbetsförmedlingen. (2020). Arbetsförmedlingens handläggarstöd. (Dnr Af-2020 / 0016 7459)
Arya, V., Bellamy, R. K. E., Chen, P., Dhurandhar, A., Hind, M., Hoffman, S. C., Houde, S., Liao, Q. V., Luss, R., Mojsilović, A., Mourad, S., Pedemonte, P., Raghavendra, R., Richards, J., Sattigeri, P., Shanmugam, K., Singh, M., Varshney, K. R., Wei, D., & Zhang, Y. (2019, September 6). One explanation does not fit all: a toolkit and taxonomy of AI explainability techniques. arXiv.org. http://arxiv.org/abs/1909.03012
Assadi, A., & Lundin, M. (2018). Street-level bureaucrats, rule-following and tenure: How assessment tools are used at the front line of the public sector. Public Administration, 96(1), 154 –170. https://doi.org/10.1111/padm.12386
Bennmarker, H., Lundin, M., Mörtlund, T., Sibbmark, K., Söderström, M., & Vikström, J. (2021). Krom – erfarenheter från en ny matchningstjänst med fristående leverantörer inom arbetsmarknadspolitiken.
Berman, A. (2023). Why does the AI say that I am too far away from the job market? In Weizenbaum Conference Proceedings 2023. AI, Big Data, Social Media, and People on the Move. Weizenbaum Institute. https://doi.org/10.34669/wi.cp/5.2
Berman, A., Breitholtz, E., Howes, C., & Bernardy, J.-P. (2022). Explaining predictions with enthymematic counterfactuals. In Proceedings of 1st Workshop on Bias, Ethical AI, Explainability and the role of Logic and Logic Programming, BEWARE-22, co-located with AIxIA 2022, University of Udine, Udine, Italy.
Berman, A., de Fine Licht, K., & Carlsson, V. (2024). Trustworthy AI in the public sector: An empirical analysis of a Swedish labor market decision-support system. Technology in Society, 76. https://doi.org/https://doi.org/10.1016/j.techsoc.2024.102471
Breitholtz, E. (2020). Enthymemes and topoi in dialogue: The use of common sense reasoning in conversation. Brill.
Busuioc, M. (2021). Accountable artificial intelligence: Holding algorithms to account. Public Administration Review, 81(5), 825 – 836.
https://doi.org/10.1111/puar.13293
Böhlmark, A., Lundström, T., & Ornstein, P. (2021). Träffsäkerhet och likabehandling vid automatiserade anvisningar inom Rusta och matcha: En kvalitetsgranskning. (Dnr Af-2020 / 0046 7913). Arbetsförmedlingen.
Carlsson, V. (2023). Legal certainty in automated decision-making in welfare services. Public Policy and Administration.
https://doi.org/10.1177/09520767231202334
Carney, T. (2020). Artificial intelligence in welfare: Striking the vulnerability balance? Monash University Law Review, 46(2), 23 – 51.
Cheng, H.-F., Wang, R., Zhang, Z., O’Connell, F., Gray, T., Harper, F. M., & Zhu, H. (2019). Explaining decision-making algorithms through UI: Strategies to help non-expert stakeholders. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems.
Colaner, N. (2022). Is explainable artificial intelligence intrinsically valuable? AI & Society, 37(1), 231– 238. https://doi.org/10.1007/s00146-021-01184-2
Dastile, X., Celik, T., & Potsane, M. (2020). Statistical and machine learning models in credit scoring: A systematic literature survey. Applied Soft Computing, 91, 106263. https://doi.org/10.1016/j.asoc.2020.106263
Desiere, S., Langenbucher, K., & Struyven, L. (2019). Statistical profiling in public employment services: An international comparison. (OECD Social, Employment and Migration Working Papers, No. 224). OECD Publishing. https://doi.org/10.1787/b5e5f16e-en
Desiere, S., & Struyven, L. (2021). Using artificial intelligence to classify jobseekers: The accuracy-equity trade-off. Journal of Social Policy, 50(2), 367 – 385. https://doi.org/doi:10.1017/S0047279420000203
Directorate-General for Parliamentary Research Services (European Parliament), Lagioia, F., & Sartor, G. (2020). The impact of the general data protection regulation on artificial intelligence. Publications Office. https://doi.org/10.2861/293
Försäkringskassan. (2005). Att skriva beslut i Försäkringskassan. (Riktlinje 2005:14, version 5. Dnr 76321-2010).
Grice, H. P. (1975). Logic and conversation. In P. Cole and J. L. Morgan (Eds.), Speech acts (pp. 41 – 58). Brill.
Grimmelikhuijsen, S. (2023). Explaining why the computer says no: Algorithmic transparency affects the perceived trustworthiness of automated decision-making. Public Administration Review, 83(2), 241 – 262.
https://doi.org/10.1111/puar.13483
Hansson, E., & Luigetti, G. (2022). Minirapport intervjuer med medarbetare: ESF-projekt Kundval rusta och matcha. (Dnr Af-2022/0026 7090). Arbetsförmedlingen.
Helgesson, P., & Ornstein, P. (2021). Vad avgör träffsäkerheten i bedömningar av arbetssökandes stödbehov? En undersökning av förutsättningarna för statistiska bedömningar av avstånd till arbetsmarknaden, med fokus på betydelsen av inskrivningstid. (Arbetsförmedlingen analys 2021:8). Arbetsförmedlingen.
Hempel, C. G., & Oppenheim, P. (1948). Studies in the logic of explanation. Philosophy of Science, 15(2), 135 –175.
Henin, C., & Le Métayer, D. (2022). Beyond explainability: Justifiability and contestability of algorithmic decision systems. AI & Society, 37(4), 1397 – 1410. https://doi.org/10.1007/s00146-021-01251-8
Kizilcec, R. F. (2016). How much information? Effects of transparency on trust in an algorithmic interface. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems.
Krishna, S., Han, T., Gu, A., Pombra, J., Jabbari, S., Wu, S., & Lakkaraju, H. (2022, February 3). The disagreement problem in Explainable Machine Learning: A Practitioner’s Perspective. arXiv.org. https://arxiv.org/abs/2202.01602
Lakkaraju, H., Slack, D., Chen, Y., Tan, C., & Singh, S. (2022, February 3). Rethinking Explainability as a Dialogue: A Practitioner’s perspective. arXiv.org. https://arxiv.org/abs/2202.01875
Lewis, D. (1979). Scorekeeping in a language game. Journal of Philosophical Logic, 8, 339 – 359.
Maraev, V., Breitholtz, E., Howes, C., & Bernardy, J.-P. (2021). Why should I turn left? Towards active explainability for spoken dialogue systems. In Proceedings of the Reasoning and Interaction Conference (ReInAct 2021).
Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 267, 1 – 38. https://doi.org/10.1016/j.artint.2018.07.007
Mittelstadt, B., Russell, C., & Wachter, S. (2019). Explaining explanations in AI. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA. https://doi.org/10.1145/3287560.3287574
Morgan, J. S. (1961). Appeals against administrative decisions under welfare legislation. Canadian Public Administration, 4(1), 44 – 60.
https://doi.org/10.1111/j.1754-7121.1961.tb00407.x
Niklas, J. D., Sztandar-Sztanderska, K., & Szymielewicz, K. (2015). Profiling the unemployed in Poland: Social and political implications of algorithmic decision making. (Fundacja Panoptykon)
Olsen, H. P., Slosser, J. L., & Hildebrandt, T. T. (2020). What’s in the box? The legal requirement to explain computationally aided decision-making in public administration. Constitutional Challenges in the Algorithmic Society. OUP. https://ssrn.com/abstract=3580128
Ornstein, P., & Thunström, H. (2021). Träffsäkerhet i bedömningen av arbetssökande. En jämförelse av arbetsförmedlare och ett statistiskt bedömningsverktyg. (Arbetsförmedlingen analys 2021:7). Arbetsförmedlingen.
Phillips, P. J., Hahn, C. A., Fontana, P. C., Yates, A. N., Greene, K., Broniatowski, D. A., & Przybocki, M. A. (2021). Four principles of explainable artificial intelligence. (NISTIR 8312). National Institute of Standards and Technology.
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939778
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5), 206–215. https://doi.org/10.1038/s42256-019-0048-x
Rudin, C., Chen, C., Chen, Z., Huang, H., Semenova, L., & Zhong, C. (2022). Interpretable machine learning: Fundamental principles and 10 grand challenges. Statistic Surveys, 16, 1– 85. https://doi.org/10.1214/21-SS133
Ruschemeier, H. (2023). The problem of the automation bias in the public sector: A legal perspective. Weizenbaum Conference Proceedings 2023. AI, Big Data, Social Media, and People on the Move. Weizenbaum Institute. https://doi.org/10.34669/wi.cp/5.6
Saxena, D., Badillo-Urquiola, K., Wisniewski, P. J., & Guha, S. (2020). A human-centered review of algorithms used within the US child welfare system. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. https://doi.org/10.1145/3313831.3376229
Sbisa, M. (2011). Acts of explanation: A speech act analysis. Perspectives and Approaches, 3, 7.
Scott, K. M., Wang, S. M., Miceli, M., Delobelle, P., Sztandar-Sztanderska, K., & Berendt, B. (2022). Algorithmic tools in public employment services: Towards a jobseeker-centric perspective. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. https://doi.org/10.1145/3531146.3534631
Simkute, A., Luger, E., Jones, B., Evans, M., & Jones, R. (2021). Explainability for experts: A design framework for making algorithms supporting expert decisions more explainable. Journal of Responsible Technology, 7, 100017. https://doi.org/10.1016/j.jrt.2021.100017
Styrelsen for Arbejdsmarked og Rekruttering. (2020, January 16). Beskrivelse af profilafklaringsværktøjet til dagpengemodtagere. Retrieved February 17, 2023, from https://star.dk/media/12514/2020_01_31_beskrivelse_-_profilafklaringsvaerktoej_til_dagpengemodtagere.pdf
Sztandar-Sztanderska, K., & Zielenska, M. (2020). What makes an ideal unemployed person? Values and norms encapsulated in a computerized profiling tool. Social Work & Society, 18(1).
Sztandar-Sztanderska, K., & Zieleńska, M. (2022). When a human says “no” to a computer: Frontline oversight of the profiling algorithm in public employment services in Poland. Sozialer Fortschritt, 71(6 – 7), 465 – 487. https://doi.org/10.3790/sfo.71.6-7.465
Tyler, T. R. (2006). Why people obey the law. Princeton University Press.
Wachter, S., Mittelstadt, B., & Russell, C. (2017). Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law & Technology, 31, 841.
Weld, D. S., & Bansal, G. (2019). The challenge of crafting intelligible intelligence. Communications of the ACM, 62(6), 70 – 79.
https://doi.org/10.1145/3282486
Zejnilovic, L., Lavado, S., Soares, C., Martínez De Rituerto De Troya, Í., Bell, A., & Ghani, R. (2021). Machine learning informed decision-making with interpreted model’s outputs: A field intervention. In Proceedings of the Academy of Management. https://doi.org/10.5465/AMBPP.2021.264
Acknowledgements
The author would like to thank the anonymous reviewers for helpful and constructive comments. This work was supported by the Swedish Research Council (VR) grant 2014 – 39 for the establishment of the Centre for Linguistic Theory and Studies in Probability (CLASP) at the University of Gothenburg.
Date received: December 2023
Date accepted: March 2024
1 The notion that human communication tends to lean on implicit premises appears in various theories and under somewhat different terminology, e.g., conversational implicature (Grice, 1975), presuppositions (Lewis, 1979), and enthymemes
(Breitholtz, 2020).
2 The term “statistical assessment support tool” is used by both the government and the Swedish PES. In this paper, the terms “AI-based” and “statistical” are used interchangeably.
3 https://www.esv.se/statsliggaren/regleringsbrev/?RBID=20264 (Accessed Jan 19, 2022)
4 A second version of Prepare and Match was introduced in April 2023. This paper focuses on the first version.
5 Arbetsförmedlingen, Bär för newbies 2.0 (Powerpoint presentation)
6 Note that the term “explainability” can be used in a variety of ways. For example, some authors use the term merely in the context of post-hoc explanations for black-box models, and distinguish it from “interpretability,” which refers to models whose internal logic is intuitively understandable for humans. This paper uses “explainability” as an umbrella term for certain desiderata in relation to explanations of AI-based decisions.
7 Although the example may be understood in terms of argumentation rather than explanation, for the purposes of the present analysis, no distinction is made between explanations and related linguistic and rhetorical phenomena, such as arguments, elaborations, and justifications.
8 To maintain a reasonable scope, the analysis focuses on positive decisions. However, most aspects of the analysis also apply to negative decisions.
9 Arbetsförmedlingen, Bär för newbies 2.0 (Powerpoint presentation)
10 This can be contrasted with an earlier algorithimic system used by the Swedish PES, where caseworkers were instructed to consider the recommended decision carefully but to also use their professional judgement (Assadi & Lundin, 2018).
11 Exactly what degree of disclosure that is reasonable concerning the enrolment criteria / threholds and their relation to volume goals is, of course, debatable. This paper does not aim to discuss general transparency considerations regarding sensitive prioritization and resource allocation issues in public decision-making, but merely stresses that some degree of transparency seems warranted from the perspective of jobseekers’ interests.
12 The suggestion assumes a linear negative mapping from estimated probability of finding a job (0 –100 %) to need for support (0 –10).
13 The comparisons are made under identical volume restrictions. If the restrictions are removed, a superior accuracy can be obtained without any statistical model at all by consistently assigning a positive decision to all jobseekers.
14 The example assumes a model that estimates duration until a job is found, which is transformed to a scale from 0 to 10.
* This is a revised and extended version of a shorter paper previously published in Weizenbaum Conference Proceedings 2023. AI, Big Data, Social Media, and People on the Move. (Berman, 2023).